

تقييم الجمهور: 27 نموذج ذكاء اصطناعي، و ChatGPT في المركز الثامن – إليك النماذج التي تفوقت عليه
على الرغم من أن عالم الذكاء الاصطناعي (AI) قد يبدو في كثير من الأحيان وكأنه منطقة غير مستقرة، إلا أن هناك قدرًا كبيرًا ومدهشًا من التحليل وقياس الأداء والاختبارات التي تجري خلف الكواليس. ليس فقط من الشركات نفسها، ولكن أيضًا من مجموعات تم إنشاؤها لتحديد تصنيفاتها الخاصة.

تختبر هذه المجموعات كل شيء، بدءًا من قدرة روبوت الدردشة على إكمال الاختبارات الرياضية،
إنشاء صور، أو تقديم تفسيرات منطقية، أو حتى إعطاء نصائح طبية، أو ببساطة إظهار مدى ذكائها العاطفي.
خلال هذه الاختبارات المتنوعة، تظهر النماذج نقاط قوتها وضعفها في مجالات مختلفة. على سبيل المثال، في حين أن GPT-5 متفوق في الاستنتاج العلمي، إلا أنه تراجع أمام أمثال Gemini و Claude في قدرته على التكيف مع المفاهيم الجديدة.
كل اختبار من هذه الاختبارات يخبرنا شيئًا جديدًا عن نماذج الذكاء الاصطناعي، وهي مهمة للتذكير بأي أداة هي الأفضل في سيناريوهات مختلفة. ولكن غالبًا ما يكون هناك قياس واحد مفقود. ببساطة، أي نماذج الذكاء الاصطناعي تقدم أفضل تجربة للمستخدم؟
نظام تصنيف Humaine
شركة تقنية مقرها المملكة المتحدة تُدعى Prolific أنشأت لوحة صدارة للذكاء الاصطناعي أطلقت عليها اسم Humaine. بدلاً من اختبار قدرة الذكاء الاصطناعي على إكمال المهام، اختبرت Prolific تجارب المستخدمين المختلفة مع هذه النماذج.
من خلال تقييم تجارب 21,352 شخصًا مع الأدوات، لم يتمكنوا فقط من إيجاد الفائز بشكل عام، بل تمكنوا أيضًا من تقسيم النتائج حسب العمر والموقع (تم الاختبار في كل من المملكة المتحدة والولايات المتحدة) والمعتقدات السياسية.
ويشمل ذلك قوائم فردية لـ:
- المملكة المتحدة: الفئات العمرية
- المملكة المتحدة: العرق
- المملكة المتحدة: وجهة النظر السياسية
- الولايات المتحدة: الفئات العمرية
- الولايات المتحدة: العرق
- الولايات المتحدة: وجهة النظر السياسية
جعل الفريق كل مشارك يتفاعل مع نموذجين منفصلين من نماذج الذكاء الاصطناعي في مقارنة، وطلب منهم تقديم ملاحظات حول النموذج الأفضل في كل تفاعل.
أدى ذلك إلى فائز ولوحة صدارة بشكل عام للأداء، ولكن أيضًا تصنيفات منفصلة للأداء الأساسي للمهام والاستدلال، بالإضافة إلى فائز في التواصل والمرونة والثقة والأخلاق.
ماذا تُظهر النتائج؟

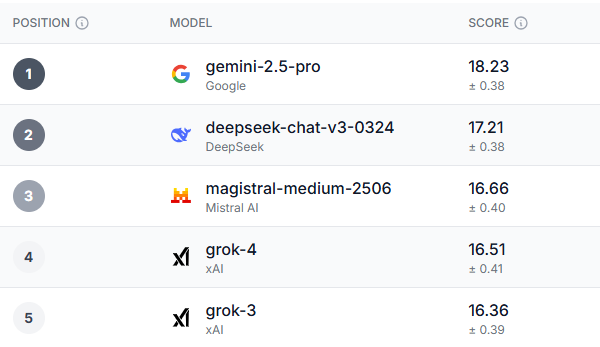
بعد استطلاع الآراء، ظهر فائز واضح جدًا، ليس فقط في فئة الأداء العام ولكن في معظم الفئات الفرعية. تفوق Gemini 2.5-Pro في كل معيار تقريبًا قدمه الاختبار.
اتفق الشباب الذين تتراوح أعمارهم بين 18 و 34 عامًا في المملكة المتحدة، والناخبون الديمقراطيون، وأولئك الذين تزيد أعمارهم عن 55 عامًا في الولايات المتحدة على أن Gemini 2.5 Pro هو أفضل نموذج بشكل عام. المجال الوحيد الذي صنفته جميع الفئات الديموغرافية أعلى من Gemini كان في الثقة والأخلاق والسلامة، وكان Grok-3 – وهو اكتشاف ساخر إلى حد ما بالنظر إلى بعض مشكلات السلامة والأخلاق التي واجهها نموذج الذكاء الاصطناعي مؤخرًا.
ومن المثير للاهتمام، أن النماذج الثلاثة التي ظهرت بعد Gemini هي Deepseek و Magistral Le Chat و Grok. في حين أن Deepseek شهد شعبية كبيرة في وقت سابق من هذا العام، إلا أنه اختفى عن الرادار مؤخرًا. من ناحية أخرى، Le Chat هو روبوت محادثة أقل شيوعًا، ولكنه يتمتع بقاعدة جماهيرية مخلصة.
إذن، أين ChatGPT المشهور عالميًا في كل هذا؟ إنه في أسفل القائمة، حيث يحتل المركز الثامن مع تصنيف نموذج GPT-4.1 الأعلى. والأسوأ من ذلك هو Claude، حيث احتلت نسختيه 4 المركزين الحادي عشر والثاني عشر في الترتيب العام.
إذًا، ما الذي يعنيه كل هذا؟
هل هذا يعني أن Gemini هو أفضل روبوت محادثة يعمل بالذكاء الاصطناعي في العالم؟ هل يعني ذلك أنه يجب عليك التخلي عن ChatGPT…؟ حسنًا، ليس بالضبط.
لا تعكس هذه النتائج بالضرورة أداء هذه النماذج. عند اختبارها على معظم المقاييس الأخرى، فإن الخيارات التي نراها عادةً في الأعلى هي ChatGPT و Gemini و Claude و Grok.
ولكن، هذه إضافة مهمة لهذه الاختبارات. فهي تساعد على فهم الذكاء الاصطناعي بشكل أفضل من منظور التجربة الإنسانية. على سبيل المثال، لا يحقق Le Chat نتائج عالية في المعايير القياسية، ولكنه غالبًا ما يُذكر كخيار ممتاز من حيث التجربة والثقة.
في حين أن أداء Anthropic و OpenAI ليس جيدًا جدًا في هذه الجولة من الاختبارات، إلا أنه أداء قوي آخر لكل من Gemini و Grok. غالبًا ما تحقق الشركتان نتائج عالية في المعايير القياسية، وقد استمرتا في القيام بذلك هنا أيضًا.
التعليقات مغلقة.