

تحقيق اليقين في نماذج اللغات الكبيرة (LLM) باستخدام دوائر اتخاذ القرار الذكية
الشك ليس جديدًا في مجال التكنولوجيا - فجميع الأنظمة الحديثة تتغلب على المدخلات والمخرجات غير المؤكدة باستخدام هياكل تحكم مثبتة رياضيًا.
إن الوعد الذي تحمله وكلاء الذكاء الاصطناعي (AI Agents) قد اجتاح العالم. يمكن للوكلاء التفاعل مع العالم من حولهم، وكتابة المقالات (ولكن ليس هذه المقالة)، واتخاذ إجراءات نيابة عنك، وبشكل عام جعل الجزء الصعب من أتمتة أي مهمة سهلاً ومتاحًا.
يستهدف الوكلاء الأجزاء الأكثر صعوبة في العمليات ويتعاملون مع المشكلات بسرعة. أحيانًا بسرعة كبيرة جدًا – إذا كانت عمليتك التي تعتمد على الوكلاء تتطلب وجود إنسان في الحلقة لاتخاذ قرار بشأن النتيجة، فقد تصبح مرحلة المراجعة البشرية عنق الزجاجة في العملية.
مثال على العملية التي تعتمد على الوكلاء هو معالجة المكالمات الهاتفية للعملاء وتصنيفها. حتى الوكيل الذي يتمتع بدقة 99.95% سيرتكب 5 أخطاء أثناء الاستماع إلى 10,000 مكالمة. على الرغم من معرفة ذلك، لا يمكن للوكيل أن يخبرك أي 5 مكالمات من بين الـ 10,000 مكالمة تم تصنيفها بشكل خاطئ.

تقنية “LLM-as-a-Judge” هي تقنية تقوم فيها بتغذية كل مدخل بعملية LLM أخرى لتقييم ما إذا كان الناتج القادم من المدخل صحيحًا. ومع ذلك، نظرًا لأن هذه عملية LLM أخرى، فقد تكون غير دقيقة أيضًا. تخلق هاتان العمليتان الاحتماليتان مصفوفة ارتباك مع الإيجابيات الحقيقية والسلبيات الكاذبة والسلبيات الحقيقية والإيجابيات الكاذبة.
بعبارة أخرى، قد يتم الحكم على المدخل المصنف بشكل صحيح بواسطة عملية LLM بأنه غير صحيح من قبل LLM القاضي الخاص به أو العكس.
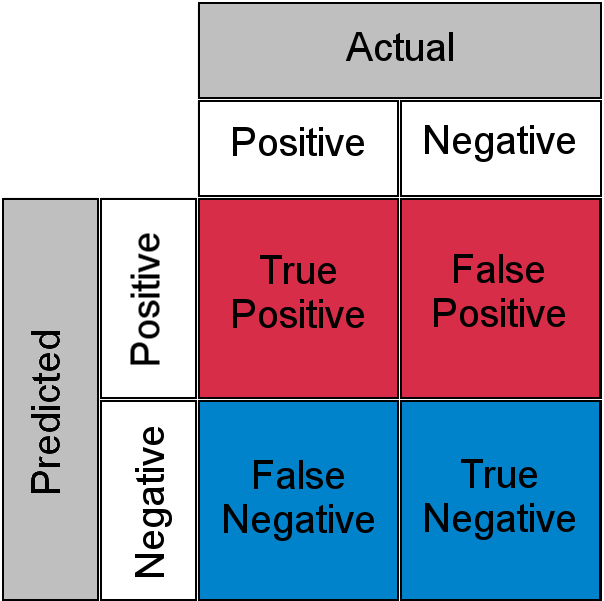
بسبب هذا ” المجهول المعروف “، بالنسبة لعبء العمل الحساس، يجب على الإنسان مراجعة وفهم جميع المكالمات الـ 10,000. لقد عدنا مرة أخرى إلى نفس مشكلة عنق الزجاجة.
كيف يمكننا بناء المزيد من اليقين الإحصائي في عملياتنا التي تعتمد على الوكلاء؟ في هذا المنشور، أقوم ببناء نظام يسمح لنا بأن نكون أكثر يقينًا في عملياتنا التي تعتمد على الوكلاء، وتعميمها على عدد عشوائي من الوكلاء، وتطوير دالة تكلفة للمساعدة في توجيه الاستثمار المستقبلي في النظام. الكود الذي استخدمه في هذا المنشور متاح في المستودع الخاص بي، ai-decision-circuits.
دوائر الذكاء الاصطناعي لاتخاذ القرارات
إن اكتشاف الأخطاء وتصحيحها ليسا بمفهومين جديدين. يعتبر تصحيح الأخطاء أمرًا بالغ الأهمية في مجالات مثل الإلكترونيات الرقمية والتناظرية. حتى التطورات في الحوسبة الكمومية تعتمد على توسيع قدرات تصحيح الأخطاء واكتشافها. يمكننا استلهام أفكار من هذه الأنظمة وتنفيذ شيء مماثل مع وكلاء الذكاء الاصطناعي. على سبيل المثال، يمكن لـ خوارزميات الذكاء الاصطناعي المتقدمة الاستفادة من تقنيات تصحيح الأخطاء الموجودة في أنظمة الاتصالات.
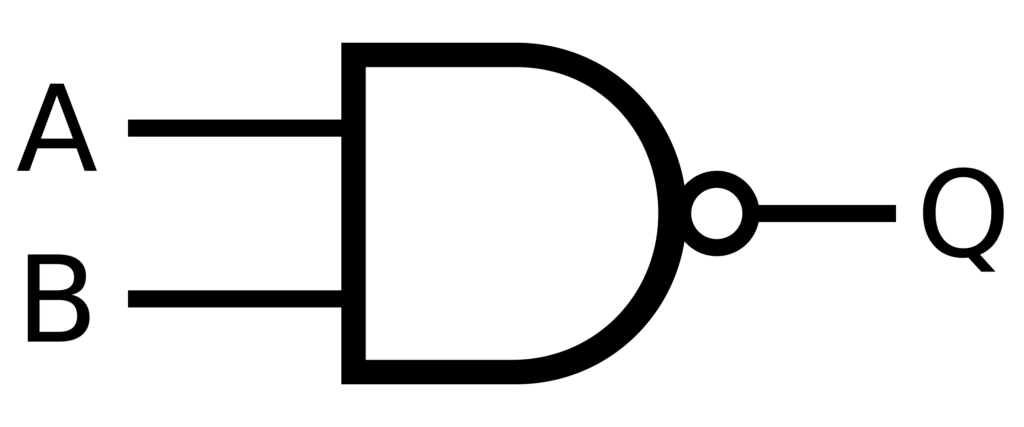
في منطق Boolean، تعتبر بوابات NAND هي الكأس المقدسة للحساب لأنها يمكن أن تؤدي أي عملية. إنها كاملة وظيفيًا، مما يعني أنه يمكن إنشاء أي عملية منطقية باستخدام بوابات NAND فقط. يمكن تطبيق هذا المبدأ على أنظمة الذكاء الاصطناعي لإنشاء هياكل قوية لاتخاذ القرارات مع تصحيح الأخطاء المدمج. هذا يسمح بإنشاء شبكات عصبونية أكثر موثوقية وقدرة على التعامل مع البيانات غير الكاملة أو المشوشة.
من الدوائر الإلكترونية إلى دوائر اتخاذ القرارات الذكية (AI)
تمامًا مثلما تستخدم الدوائر الإلكترونية التكرار والتحقق لضمان حسابات موثوقة، يمكن لدوائر اتخاذ القرارات الذكية (AI) أن تستخدم وكلاء متعددين بوجهات نظر مختلفة للوصول إلى نتائج أكثر دقة. يمكن بناء هذه الدوائر باستخدام مبادئ من نظرية المعلومات ومنطق Boolean:
- المعالجة المتكررة (Redundant Processing): يقوم العديد من وكلاء الذكاء الاصطناعي بمعالجة نفس المدخلات بشكل مستقل، على غرار كيفية استخدام وحدات المعالجة المركزية (CPUs) الحديثة لدوائر متكررة للكشف عن أخطاء الأجهزة. هذه العملية تزيد من موثوقية نظام الذكاء الاصطناعي.
- آليات الإجماع (Consensus Mechanisms): يتم دمج مخرجات القرار باستخدام أنظمة التصويت أو المتوسطات المرجحة، على غرار بوابات المنطق الأغلبي في الإلكترونيات المتسامحة مع الأخطاء. هذه الآليات تضمن أن القرار النهائي يعكس توافق الآراء بين الوكلاء.
- وكلاء التحقق (Validator Agents): يتحقق مدققو الذكاء الاصطناعي المتخصصون من مدى معقولية المخرجات، ويعملون بشكل مشابه لرموز اكتشاف الأخطاء مثل بتات التكافؤ (Parity bits) أو فحوصات التكرار الدوري (CRC checks). هذه الوكلاء يقللون من احتمالية اتخاذ قرارات خاطئة.
- دمج العنصر البشري في الحلقة (Human-in-the-Loop Integration): التحقق البشري الاستراتيجي في النقاط الرئيسية في عملية اتخاذ القرار، على غرار كيفية استخدام الأنظمة الحيوية للإشراف البشري كطبقة التحقق النهائية. هذا يضمن أن القرارات الهامة تخضع لتقييم بشري.
الأسس الرياضية لدوائر اتخاذ القرار في الذكاء الاصطناعي
يمكن تحديد موثوقية هذه الأنظمة كميًا باستخدام نظرية الاحتمالات.
بالنسبة لعامل واحد، يأتي احتمال الفشل من الدقة المرصودة بمرور الوقت عبر مجموعة بيانات اختبار، مخزنة في نظام مثل LangSmith.

بالنسبة لعامل دقيق بنسبة 90%، فإن احتمال الفشل، p_1، 1–0.9 هو 0.1، أو 10%.

إن احتمال فشل عاملين مستقلين على نفس المدخلات هو احتمال دقة كلا العاملين مضروبًا معًا:
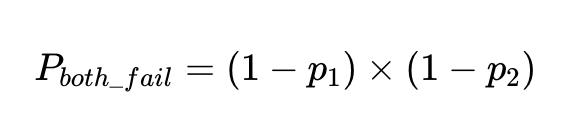
إذا كان لدينا N عملية تنفيذ مع هؤلاء العملاء، فإن العدد الإجمالي للإخفاقات هو
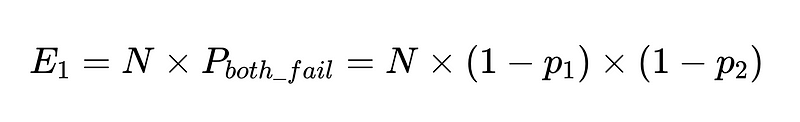
لذلك بالنسبة إلى 10,000 عملية تنفيذ بين عاملين مستقلين بدقة 90%، فإن العدد المتوقع للإخفاقات هو 100 إخفاق.
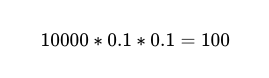
ومع ذلك، ما زلنا لا نعرف أي من تلك المكالمات الهاتفية الـ 10,000 هي الإخفاقات الـ 100 الفعلية.
يمكننا دمج أربعة امتدادات لهذه الفكرة لتقديم حل أكثر قوة يوفر الثقة في أي استجابة معينة:
- مصنف أساسي (دقة بسيطة أعلاه)
- مصنف احتياطي (دقة بسيطة أعلاه)
- مدقق المخطط (دقة 0.7 على سبيل المثال)

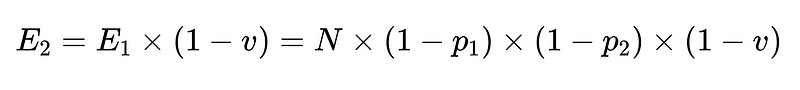
- وأخيرًا، مدقق سلبي (n = دقة 0.6 على سبيل المثال)
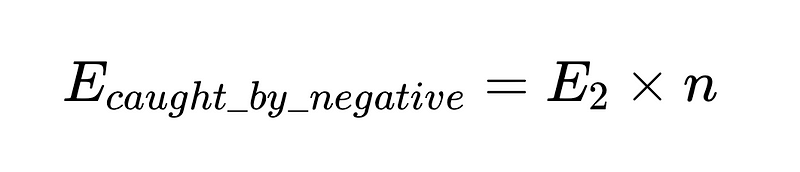
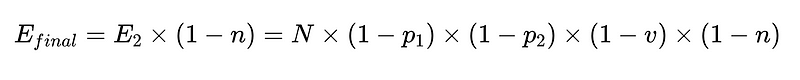
لوضع هذا في التعليمات البرمجية (المستودع الكامل)، يمكننا استخدام Python بسيط:
def primary_parser(self, customer_input: str) -> Dict[str, str]:
"""
Primary parser: Direct command with format expectations.
"""
prompt = f"""
Extract the category of the customer service call from the following text as a JSON object with key 'call_type'.
The call type must be one of: {', '.join(self.call_types)}.
If the category cannot be determined, return {{'call_type': null}}.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
try:
# Try to parse the response as JSON
result = json.loads(response.content.strip())
return result
except json.JSONDecodeError:
# If JSON parsing fails, try to extract the call type from the text
for call_type in self.call_types:
if call_type in response.content:
return {"call_type": call_type}
return {"call_type": None}
def backup_parser(self, customer_input: str) -> Dict[str, str]:
"""
Backup parser: Chain of thought approach with formatting instructions.
"""
prompt = f"""
First, identify the main issue or concern in the customer's message.
Then, match it to one of the following categories: {', '.join(self.call_types)}.
Think through each category and determine which one best fits the customer's issue.
Return your answer as a JSON object with key 'call_type'.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
try:
# Try to parse the response as JSON
result = json.loads(response.content.strip())
return result
except json.JSONDecodeError:
# If JSON parsing fails, try to extract the call type from the text
for call_type in self.call_types:
if call_type in response.content:
return {"call_type": call_type}
return {"call_type": None}
def negative_checker(self, customer_input: str) -> str:
"""
Negative checker: Determines if the text contains enough information to categorize.
"""
prompt = f"""
Does this customer service call contain enough information to categorize it into one of these types:
{', '.join(self.call_types)}?
Answer only 'yes' or 'no'.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
answer = response.content.strip().lower()
if "yes" in answer:
return "yes"
elif "no" in answer:
return "no"
else:
# Default to yes if the answer is unclear
return "yes"
@staticmethod
def validate_call_type(parsed_output: Dict[str, Any]) -> bool:
"""
Schema validator: Checks if the output matches the expected schema.
"""
# Check if output matches expected schema
if not isinstance(parsed_output, dict) or 'call_type' not in parsed_output:
return False
# Verify the extracted call type is in our list of known types or null
call_type = parsed_output['call_type']
return call_type is None or call_type in CALL_TYPESمن خلال الجمع بين هذه العمليات مع منطق Boolean بسيط، يمكننا الحصول على دقة مماثلة جنبًا إلى جنب مع الثقة في كل إجابة:
def combine_results(
primary_result: Dict[str, str],
backup_result: Dict[str, str],
negative_check: str,
validation_result: bool,
customer_input: str
) -> Dict[str, str]:
"""
Combiner: Combines the results from different strategies.
"""
# If validation failed, use backup
if not validation_result:
if RobustCallClassifier.validate_call_type(backup_result):
return backup_result
else:
return {"call_type": None, "confidence": "low", "needs_human": True}
# If negative check says no call type can be determined but we extracted one, double-check
if negative_check == 'no' and primary_result['call_type'] is not None:
if backup_result['call_type'] is None:
return {'call_type': None, "confidence": "low", "needs_human": True}
elif backup_result['call_type'] == primary_result['call_type']:
# Both agree despite negative check, so go with it but mark low confidence
return {'call_type': primary_result['call_type'], "confidence": "medium"}
else:
return {"call_type": None, "confidence": "low", "needs_human": True}
# If primary and backup agree, high confidence
if primary_result['call_type'] == backup_result['call_type'] and primary_result['call_type'] is not None:
return {'call_type': primary_result['call_type'], "confidence": "high"}
# Default: use primary result with medium confidence
if primary_result['call_type'] is not None:
return {'call_type': primary_result['call_type'], "confidence": "medium"}
else:
return {'call_type': None, "confidence": "low", "needs_human": True}
منطق اتخاذ القرار: شرح تفصيلي خطوة بخطوة
الخطوة 1: عند فشل نظام مراقبة الجودة
if not validation_result:هذا يعني: “إذا رفض خبير مراقبة الجودة لدينا (المدقق) التحليل الأولي، فلا تثق به.” يحاول النظام بعد ذلك استخدام الرأي الاحتياطي بدلاً من ذلك. وإذا فشل هذا أيضًا في التحقق، فإنه يضع علامة على الحالة لمراجعتها من قبل مختص بشري. هذا الإجراء يضمن عدم الاعتماد على بيانات غير دقيقة.
بعبارات بسيطة: “إذا كان هناك شيء غير صحيح بشأن إجابتنا الأولى، فلنجرب طريقتنا الاحتياطية. وإذا كان ذلك لا يزال مشكوكًا فيه، فلنطلب تدخل خبير بشري.” هذا يضمن معالجة الحالات المعقدة بشكل صحيح.
الخطوة 2: معالجة التناقضات
if negative_check == 'no' and primary_result['call_type'] is not None:تتحقق هذه الخطوة من نوع معين من التناقضات: “يشير مدقق السلبية لدينا إلى أنه لا ينبغي أن يكون هناك نوع مكالمة، ولكن المحلل الأساسي لدينا وجد نوعًا على أي حال.”
في مثل هذه الحالات، يعتمد النظام على المحلل الاحتياطي لكسر التعادل:
- إذا وافق المحلل الاحتياطي على عدم وجود نوع مكالمة ← يتم إرسالها إلى العنصر البشري
- إذا وافق المحلل الاحتياطي المحلل الأساسي ← يتم القبول ولكن بثقة متوسطة
- إذا كان لدى المحلل الاحتياطي نوع مكالمة مختلف ← يتم إرسالها إلى العنصر البشري
هذا يشبه القول: “إذا قال أحد الخبراء “هذا غير قابل للتصنيف” ولكن آخر يقول إنه كذلك، فنحن بحاجة إلى فاصل للتعادل أو حكم بشري.” هذه الآلية ضرورية لضمان دقة تصنيف أنواع المكالمات وتقليل الأخطاء المحتملة.
الخطوة 3: عندما يتفق الخبراء
if primary_result['call_type'] == backup_result['call_type'] and primary_result['call_type'] is not None:عندما يتوصل كل من المحلل الأساسي والاحتياطي بشكل مستقل إلى نفس النتيجة، يضع النظام علامة “ثقة عالية” – وهذا هو أفضل سيناريو. هذه الحالة المثالية تحدث عندما تتطابق تحليلات متعددة بشكل قاطع.
بمعنى مبسط: “إذا توصل خبيران مختلفان باستخدام طرق مختلفة إلى نفس الاستنتاج بشكل مستقل، فيمكننا أن نكون واثقين تمامًا من صحة استنتاجهما.” هذا يمثل توافق آراء الخبراء، وهو مؤشر قوي على الدقة والموثوقية.
الخطوة 4: المعالجة الافتراضية
في حال عدم انطباق أي من الحالات الخاصة، يعود النظام افتراضيًا إلى نتيجة المحلل الأساسي بثقة “متوسطة”. وإذا لم يتمكن المحلل الأساسي نفسه من تحديد نوع المكالمة، فإنه يضع علامة على الحالة لمراجعتها من قبل محلل بشري متخصص.
أهمية هذا النهج في تقليل الأخطاء
يساهم هذا المنطق في بناء نظام قوي من خلال:
- تقليل النتائج الإيجابية الخاطئة: لا يمنح النظام ثقة عالية إلا عندما تتفق طرق متعددة، مما يقلل بشكل كبير من الإنذارات الكاذبة.
- اكتشاف التناقضات: عندما تختلف أجزاء مختلفة من النظام، فإنه إما يقلل الثقة أو يصعد الأمر إلى المراجعين البشريين، مما يضمن عدم تجاهل أي مشكلة محتملة.
- التصعيد الذكي: لا يرى المراجعون البشريون سوى الحالات التي تحتاج حقًا إلى خبراتهم، مما يزيد من كفاءة عملية المراجعة ويقلل من إجهاد الموارد البشرية.
- تسمية الثقة: تتضمن النتائج مستوى ثقة النظام، مما يسمح للعمليات اللاحقة بمعاملة النتائج عالية الثقة مقابل المتوسطة بشكل مختلف، وهو أمر بالغ الأهمية لاتخاذ قرارات مستنيرة.
يشبه هذا النهج الطريقة التي تستخدم بها الإلكترونيات دوائر زائدة وآليات تصويت لمنع الأخطاء من التسبب في فشل النظام. في أنظمة الذكاء الاصطناعي، يمكن لهذا النوع من منطق الدمج المدروس أن يقلل بشكل كبير من معدلات الخطأ مع استخدام المراجعين البشريين بكفاءة فقط حيث يضيفون أكبر قيمة. هذا يضمن تحسين الموارد وتقليل الأخطاء في آن واحد، مما يؤدي إلى نظام أكثر موثوقية ودقة.
مثال
في عام 2015، نشرت إدارة المياه في مدينة فيلادلفيا إحصائيات مكالمات العملاء حسب الفئة. يُعد فهم مكالمات العملاء عملية شائعة جدًا يتعامل معها الوكلاء. فبدلاً من استماع شخص بشري إلى كل مكالمة هاتفية للعميل، يمكن للوكيل الاستماع إلى المكالمة بسرعة أكبر بكثير، واستخراج المعلومات، وتصنيف المكالمة لمزيد من تحليل البيانات. بالنسبة لإدارة المياه، هذا مهم لأنه كلما تم تحديد المشكلات الحرجة بشكل أسرع، كلما أمكن حل هذه المشكلات في وقت أقرب.
يمكننا بناء تجربة. استخدمت نموذج لغوي كبير (LLM) لإنشاء نصوص مزيفة للمكالمات الهاتفية المعنية عن طريق مطالبة “بالنظر إلى الفئة التالية، قم بإنشاء نسخة قصيرة من تلك المكالمة الهاتفية: <category>”. فيما يلي بعض هذه الأمثلة مع الملف الكامل المتاح هنا:
{
"calls": [
{
"id": 5,
"type": "ABATEMENT",
"customer_input": "I need to report an abandoned property that has a major leak. Water is pouring out and flooding the sidewalk."
},
{
"id": 7,
"type": "AMR (METERING)",
"customer_input": "Can someone check my water meter? The digital display is completely blank and I can't read it."
},
{
"id": 15,
"type": "BTR/O (BAD TASTE & ODOR)",
"customer_input": "My tap water smells like rotten eggs. Is it safe to drink?"
}
]
}الآن، يمكننا إعداد التجربة بتقييم أكثر تقليدية باستخدام نموذج لغوي كبير كحكم (التنفيذ الكامل هنا):
def classify(customer_input):
CALL_TYPES = [
"RESTORE", "ABATEMENT", "AMR (METERING)", "BILLING", "BPCS (BROKEN PIPE)", "BTR/O (BAD TASTE & ODOR)",
"C/I - DEP (CAVE IN/DEPRESSION)", "CEMENT", "CHOKED DRAIN", "CLAIMS", "COMPOST"
]
model = ChatAnthropic(model='claude-3-7-sonnet-latest')
prompt = f"""
You are a customer service AI for a water utility company. Classify the following customer input into one of these categories:
{', '.join(CALL_TYPES)}
Customer input: "{customer_input}"
Respond with just the category name, nothing else.
"""
# Get the response from Claude
response = model.invoke(prompt)
predicted_type = response.content.strip()
return predicted_typeعن طريق تمرير النص فقط إلى النموذج اللغوي الكبير (LLM)، يمكننا عزل معرفة الفئة الحقيقية عن الفئة المستخرجة التي يتم إرجاعها ومقارنتها.
def compare(customer_input, actual_type)
predicted_type = classify(customer_input)
result = {
"id": call["id"],
"customer_input": customer_input,
"actual_type": actual_type,
"predicted_type": predicted_type,
"correct": actual_type == predicted_type
}
return resultتشغيل هذا على مجموعة البيانات المصطنعة بأكملها باستخدام Claude 3.7 Sonnet (أحدث نموذج، حتى كتابة هذه السطور)، يكون عالي الأداء للغاية حيث يتم تصنيف 91% من المكالمات بدقة:
"metrics": {
"overall_accuracy": 0.91,
"correct": 91,
"total": 100
}إذا كانت هذه مكالمات حقيقية ولم تكن لدينا معرفة مسبقة بالفئة، فسنظل بحاجة إلى مراجعة جميع المكالمات الهاتفية الـ 100 للعثور على المكالمات الـ 9 المصنفة بشكل خاطئ.
من خلال تطبيق دارة اتخاذ القرار القوية الخاصة بنا أعلاه، نحصل على نتائج دقة مماثلة إلى جانب الثقة في تلك الإجابات. في هذه الحالة، دقة إجمالية تبلغ 87% ولكن دقة تبلغ 92.5% في إجاباتنا عالية الثقة.
{
"metrics": {
"overall_accuracy": 0.87,
"correct": 87,
"total": 100
},
"confidence_metrics": {
"high": {
"count": 80,
"correct": 74,
"accuracy": 0.925
},
"medium": {
"count": 18,
"correct": 13,
"accuracy": 0.722
},
"low": {
"count": 2,
"correct": 0,
"accuracy": 0.0
}
}
}نحن بحاجة إلى دقة 100% في إجاباتنا عالية الثقة لذلك لا يزال هناك عمل يتعين القيام به. ما يتيح لنا هذا النهج هو التعمق في سبب عدم دقة الإجابات عالية الثقة. في هذه الحالة، لا تلتقط المطالبة الضعيفة وقدرة التحقق البسيطة جميع المشكلات، مما يؤدي إلى أخطاء في التصنيف. يمكن تحسين هذه القدرات بشكل متكرر لتحقيق دقة 100% في الإجابات عالية الثقة.
تحسينات في نظام الفلترة لزيادة الثقة في النتائج
يقوم النظام الحالي بتصنيف الاستجابات على أنها “عالية الثقة” عندما يتفق المحللان الأساسي والاحتياطي. لتحقيق دقة أعلى، يجب أن نكون أكثر انتقائية بشأن ما يعتبر “عالي الثقة”.
# Modified high confidence logic
if (primary_result['call_type'] == backup_result['call_type'] and
primary_result['call_type'] is not None and
validation_result and
negative_check == 'yes' and
additional_validation_metrics > threshold):
return {'call_type': primary_result['call_type'], "confidence": "high"}من خلال إضافة معايير تأهيل إضافية، سنحصل على عدد أقل من النتائج “عالية الثقة”، ولكنها ستكون أكثر دقة. هذا التحسين في نظام الفلترة يهدف إلى تقليل الأخطاء وزيادة موثوقية البيانات المصنفة على أنها ذات جودة عالية.
تقنيات تحقق إضافية: تعزيز دقة التحليل
فيما يلي بعض الأفكار الأخرى لتعزيز عملية التحقق من صحة البيانات والتحليلات:
محلل ثلاثي (Tertiary Analyzer): إضافة طريقة تحليل مستقلة ثالثة. يعتبر هذا الأسلوب بمثابة طبقة إضافية من التحقق، حيث يقارن نتائج طريقتين تحليليتين مختلفتين مع نتيجة الطريقة الثالثة، لضمان دقة أكبر وتقليل احتمالية الأخطاء.
# Only mark high confidence if all three agree
if primary_result['call_type'] == backup_result['call_type'] == tertiary_result['call_type']:مطابقة الأنماط التاريخية (Historical Pattern Matching): قارن النتائج مع النتائج الصحيحة تاريخيًا (فكر في البحث المتجهي). تستخدم هذه التقنية بيانات تاريخية موثوقة كمرجع، وتقارن النتائج الحالية بها لتحديد أي انحرافات أو تناقضات. يمكن اعتبارها نوعًا من “الذاكرة” للتحليل، مما يساعد في اكتشاف الحالات الشاذة أو غير المتوقعة.
if similarity_to_known_correct_cases(primary_result) > 0.95:الاختبار المعادي (Adversarial Testing): قم بتطبيق اختلافات صغيرة على المدخلات وتحقق مما إذا كان التصنيف يظل مستقرًا. يهدف هذا الأسلوب إلى اختبار مدى قوة وصلابة نظام التصنيف، من خلال تعريضه لتغيرات طفيفة في البيانات. إذا كان النظام حساسًا للغاية لهذه التغييرات، فقد يشير ذلك إلى وجود نقاط ضعف أو تحيزات محتملة.
variations = generate_input_variations(customer_input)
if all(analyze_call_type(var) == primary_result['call_type'] for var in variations):
صيغة عامة للتدخلات البشرية في نظام استخلاص LLM
- N = العدد الإجمالي للتنفيذات (10,000 في مثالنا)
- p_1 = دقة المحلل اللغوي الأساسي (0.8 في مثالنا)
- p_2 = دقة المحلل اللغوي الاحتياطي (0.8 في مثالنا)
- v = فعالية مدقق المخطط (schema validator) (0.7 في مثالنا)
- n = فعالية المدقق السلبي (negative checker) (0.6 في مثالنا)
- H = عدد التدخلات البشرية المطلوبة
- E_final = الأخطاء النهائية غير المكتشفة
- m = عدد المدققين المستقلين
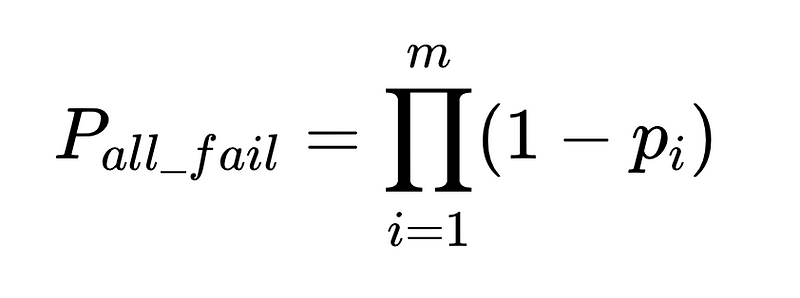
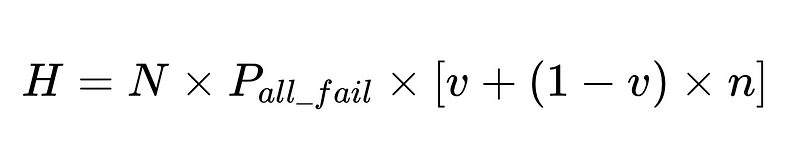
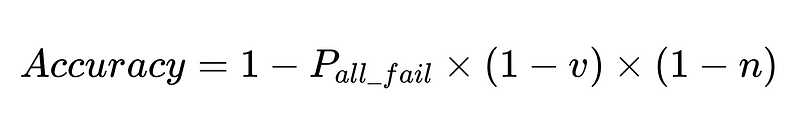
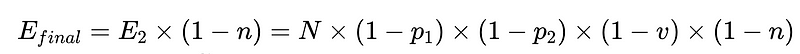
تصميم النظام الأمثل
تكشف المعادلة رؤى أساسية حول دقة نظام معالجة اللغة الطبيعية (NLP):
- إضافة المحللات اللغوية (parsers) يقلل من العائدات ولكن يحسن الدقة بشكل عام.
- دقة النظام محدودة بـ:
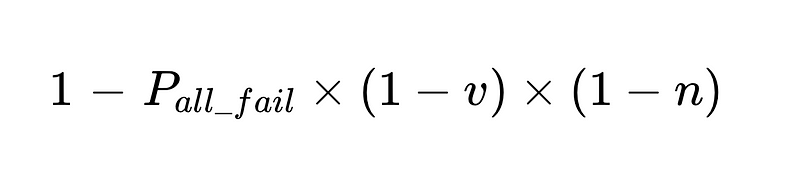
- التدخلات البشرية تتناسب طرديًا مع إجمالي عمليات التنفيذ N.
على سبيل المثال:
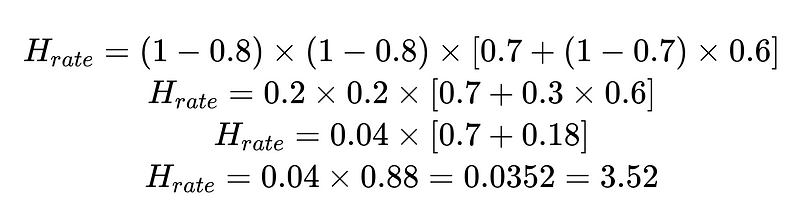
يمكننا استخدام معدل التدخل البشري (H_rate) المحسوب لتتبع فعالية الحل الخاص بنا في الوقت الفعلي. إذا بدأ معدل التدخل البشري في الارتفاع فوق 3.5%، فإننا نعلم أن النظام يتعطل. وإذا كان معدل التدخل البشري يتناقص باستمرار إلى أقل من 3.5%، فإننا نعلم أن تحسيناتنا تعمل على النحو المتوقع.
دالة التكلفة
يمكننا أيضًا إنشاء دالة تكلفة تساعدنا في تحسين نظامنا. تُعد دالة التكلفة أداة تحليلية قوية لتقييم الأداء المالي للنظام وتحديد مجالات التحسين المحتملة.
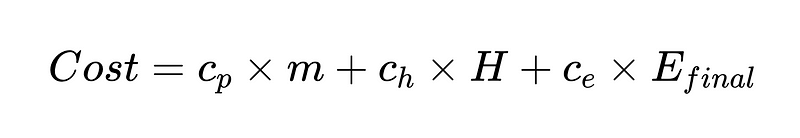
حيث:
- c_p = تكلفة التشغيل لكل محلل نحوي (0.10 دولار أمريكي في مثالنا)
- m = عدد مرات تنفيذ المحلل النحوي (في مثالنا 2 * N)
- H = عدد الحالات التي تتطلب تدخلًا بشريًا (352 من مثالنا)
- c_h = تكلفة التدخل البشري الواحد (200 دولار أمريكي على سبيل المثال: 4 ساعات بسعر 50 دولارًا/للساعة)
- c_e = تكلفة الخطأ الواحد غير المكتشف (1000 دولار أمريكي على سبيل المثال)
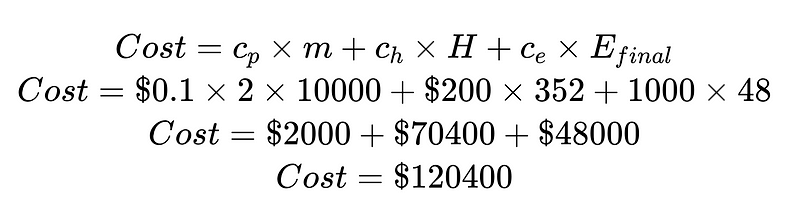
من خلال تقسيم التكلفة حسب تكلفة التدخل البشري وتكلفة الخطأ غير المكتشف، يمكننا تحسين النظام بشكل عام. في هذا المثال، إذا كانت تكلفة التدخل البشري (70,400 دولارًا أمريكيًا) غير مرغوبة وباهظة التكلفة، فيمكننا التركيز على زيادة النتائج عالية الثقة. وإذا كانت تكلفة الأخطاء غير المكتشفة (48,000 دولارًا أمريكيًا) غير مرغوبة وباهظة التكلفة، فيمكننا إدخال المزيد من المحللات النحوية لخفض معدلات الأخطاء غير المكتشفة.
بالطبع، تكون دوال التكلفة أكثر فائدة كطرق لاستكشاف كيفية تحسين الحالات التي تصفها.
من السيناريو أعلاه، لتقليل عدد الأخطاء غير المكتشفة، E_final، بنسبة 50%، حيث
- p1 و p2 = 0.8،
- v = 0.7 و
- n = 0.6
لدينا ثلاثة خيارات:
- إضافة محلل نحوي جديد بدقة 50% وإدراجه كمحلل ثانوي. تجدر الإشارة إلى أن هذا يأتي مع مفاضلة: تزداد تكلفة تشغيل المزيد من المحللات النحوية جنبًا إلى جنب مع الزيادة في تكلفة التدخل البشري.
- تحسين المحللين النحويين الحاليين بنسبة 10% لكل منهما. قد يكون ذلك ممكنًا أو غير ممكن نظرًا لصعوبة المهمة التي يؤديها هؤلاء المحللون النحويون.
- تحسين عملية المدقق بنسبة 15%. مرة أخرى، هذا يزيد التكلفة عن طريق التدخل البشري.
مستقبل موثوقية الذكاء الاصطناعي: بناء الثقة من خلال الدقة المتناهية
مع تزايد دمج أنظمة الذكاء الاصطناعي في الجوانب الحيوية للأعمال والمجتمع، سيصبح السعي وراء الدقة المثالية ضرورة ملحة، خاصة في التطبيقات الحساسة. من خلال تبني هذه المناهج المستوحاة من الدوائر الإلكترونية في اتخاذ قرارات الذكاء الاصطناعي، يمكننا بناء أنظمة لا تتوسع بكفاءة فحسب، بل وتكتسب أيضًا الثقة العميقة التي لا تأتي إلا من الأداء المتسق والموثوق. المستقبل لا يكمن في النماذج الفردية الأكثر قوة، بل في الأنظمة المصممة بعناية والتي تجمع بين وجهات نظر متعددة مع رقابة بشرية استراتيجية.
تمامًا كما تطورت الإلكترونيات الرقمية من مكونات غير موثوقة لإنشاء أجهزة كمبيوتر نثق بها في بياناتنا الأكثر أهمية، فإن أنظمة الذكاء الاصطناعي الآن في رحلة مماثلة. تمثل الأطر الموصوفة في هذه المقالة المخططات الأولية لما سيصبح في النهاية البنية القياسية للذكاء الاصطناعي ذي المهام الحرجة – الأنظمة التي لا تعد فقط بالموثوقية، بل تضمنها رياضيًا. السؤال لم يعد ما إذا كان بإمكاننا بناء أنظمة الذكاء الاصطناعي بدقة شبه مثالية، ولكن إلى أي مدى يمكننا تنفيذ هذه المبادئ بسرعة عبر أهم تطبيقاتنا.
التعليقات مغلقة.