

تعمل نماذج رؤية Transformer الحديثة على إضافة ضوضاء لتحسين أداء الكشف عن الأجسام ثنائية وثلاثية الأبعاد. سنتعلم في هذه المقالة كيف تعمل هذه الآلية ونناقش مساهمتها في تحسين دقة نماذج الكشف عن الأجسام، مع التركيز على استخدام تقنيات مثل Denoising في عملية التدريب.

نماذج Transformer للرؤية المبكرة
DETR – DEtection TRansformer (Carion, Massa et al. 2020)، أحد أوائل Architectures لـ Transformer لاكتشاف الكائنات، استخدم استعلامات وحدة فك الترميز المتعلمة لاستخراج معلومات الاكتشاف من رموز الصور. تم تهيئة هذه الاستعلامات عشوائيًا، ولم يفرض Architecture أي قيود أجبرت هذه الاستعلامات على تعلم أشياء تشبه المراسي. بينما حقق نتائج مماثلة مع Faster-RCNN، كان عيبه في التقارب البطيء – 500 حقبة كانت مطلوبة لتدريبه (DN-DETR, Li et al., 2024). استخدمت Architectures الأحدث المستندة إلى DETR تجميعًا قابلاً للتشوه مكن الاستعلامات من التركيز فقط على مناطق معينة في الصورة (Zhu et al., Deformable DETR: Deformable Transformers For End-To-End Object Detection, 2020)، بينما استخدم آخرون (Liu et al., DAB-DETR: Dynamic Anchor Boxes Are Better Queries For DETR, 2022) مراسي مكانية (تم إنشاؤها باستخدام k-means، بطريقة مماثلة للطريقة التي تفعل بها CNNs المستندة إلى المرساة)، والتي تم ترميزها في الاستعلامات الأولية. أجبرت اتصالات التخطي كتلة وحدة فك ترميز Transformer على تعلم المربعات كقيم انحدار من المراسي. استخدمت طبقات الانتباه القابلة للتشوه المراسي المشفرة مسبقًا لأخذ عينات من الميزات المكانية من الصورة واستخدامها لإنشاء رموز للانتباه. خلال التدريب، يتعلم النموذج المراسي المثالية للاستخدام. يعلم هذا النهج النموذج لاستخدام ميزات مثل حجم الصندوق بشكل صريح في استعلاماته.
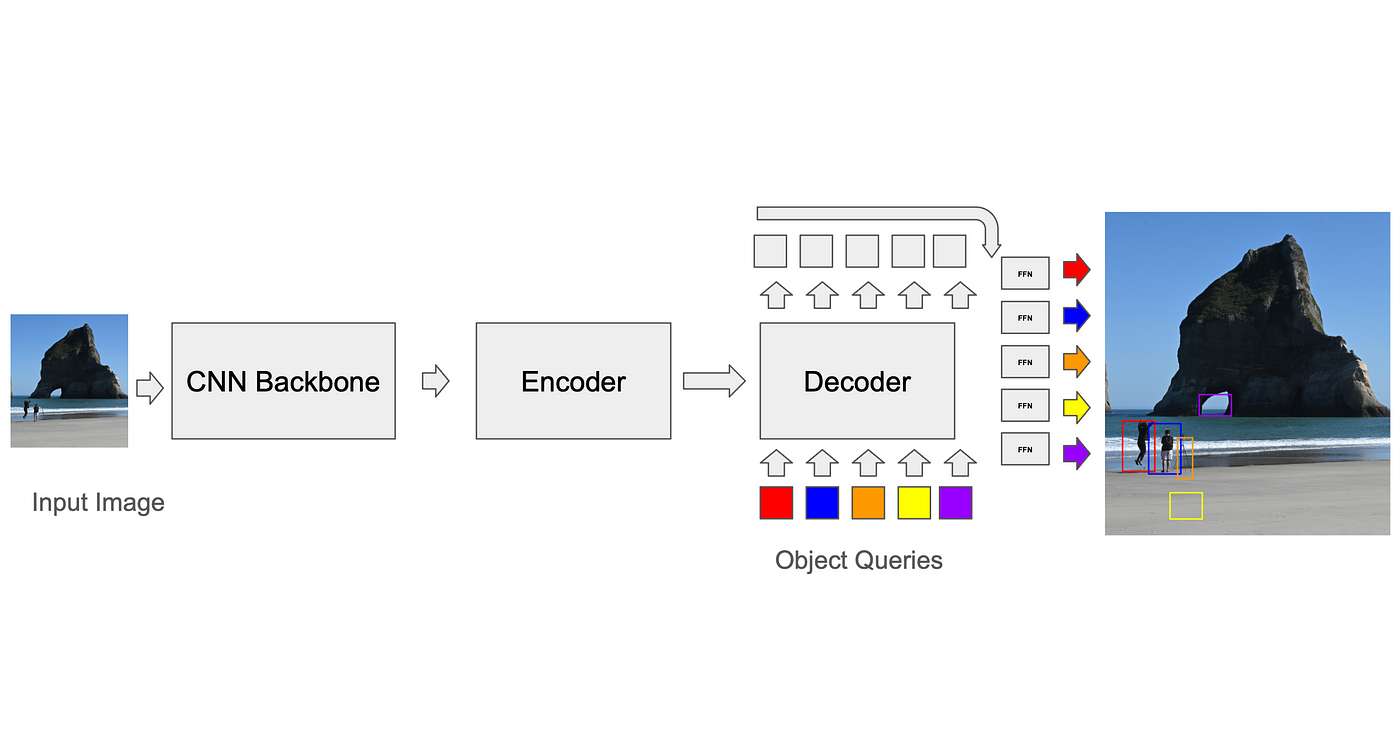
مطابقة التوقعات مع الحقائق الأساسية: خوارزمية المطابقة الثنائية
لحساب الخسارة، يحتاج المدرب أولاً إلى مطابقة توقعات النموذج مع الصناديق ذات الحقائق الأساسية (GT). في حين أن شبكات CNN القائمة على المرساة لديها حلول سهلة نسبيًا لهذه المشكلة (على سبيل المثال، يمكن مطابقة كل مرساة فقط مع صناديق GT في فوكسل الخاص بها أثناء التدريب، وفي الاستدلال، يتم استخدام تثبيط غير الأقصى لإزالة الاكتشافات المتداخلة)، فإن المعيار الخاص بالمحولات، الذي وضعه DETR، هو استخدام خوارزمية مطابقة ثنائية تسمى خوارزمية هنغارية. في كل تكرار، تجد الخوارزمية أفضل مطابقة بين التوقع والحقيقة الأساسية (مطابقة تعمل على تحسين دالة التكلفة، مثل متوسط المسافة التربيعية بين زوايا الصندوق، مجموعًا على جميع الصناديق). ثم يتم حساب الخسارة بين أزواج صندوق التوقع-الحقيقة الأساسية ويمكن نشرها عكسيًا. تتكبد التوقعات الزائدة (التوقع بدون مطابقة GT) خسارة منفصلة تشجعها على تقليل درجة الثقة بها. هذه العملية ضرورية لتحسين دقة النموذج وتقليل الأخطاء.
المشكلة
يبلغ التعقيد الزمني لخوارزمية Hungarian o(n³). ومن المثير للاهتمام أن هذا ليس بالضرورة عنق الزجاجة في جودة التدريب: فقد تبين (The Stable Marriage Problem: An Interdisciplinary Review From The Physicist’s Perspective, Fenoaltea et al., 2021) أن الخوارزمية غير مستقرة، بمعنى أن تغييراً طفيفاً في دالة الهدف الخاصة بها قد يؤدي إلى تغيير كبير في نتيجة المطابقة الخاصة بها – مما يؤدي إلى أهداف تدريب استعلام غير متناسقة. والآثار العملية في تدريب المحولات هي أن استعلامات الكائنات يمكن أن تقفز بين الكائنات وتستغرق وقتاً طويلاً لتعلم أفضل الميزات للتقارب. وبعبارة أخرى، عدم استقرار الخوارزمية يؤدي إلى تذبذب في عملية التدريب، مما يتطلب وقتاً أطول للوصول إلى أفضل النتائج.
DN-DETR (كشف الكائنات بالتخلص من الضوضاء)
اقترح Li وآخرون حلاً أنيقًا لمشكلة المطابقة غير المستقرة، وقد تم تبنيه لاحقًا في العديد من الأعمال الأخرى، بما في ذلك DINO و Mask DINO و Group DETR وغيرها.
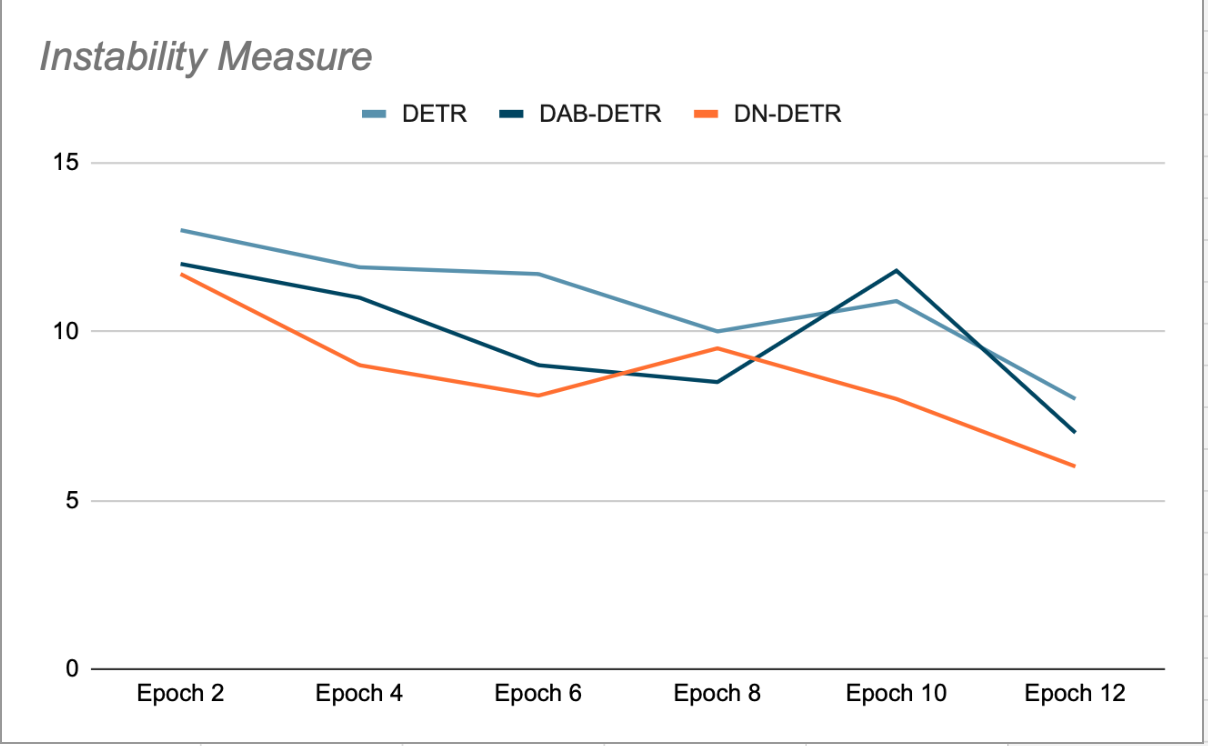
تعتمد الفكرة الرئيسية في DN-DETR على تعزيز التدريب عن طريق إنشاء نقاط ارتكاز وهمية سهلة الانحدار، تتخطى عملية المطابقة. يتم ذلك أثناء التدريب عن طريق إضافة كمية صغيرة من الضوضاء إلى مربعات GT (الأرض الحقيقية) وتغذية هذه المربعات المشوشة كمرتكزات لاستعلامات وحدة فك التشفير. يتم إخفاء استعلامات DN عن الاستعلامات العضوية والعكس صحيح، لتجنب الانتباه المتبادل الذي قد يتداخل مع التدريب. عمليات الكشف التي يتم إنشاؤها بواسطة هذه الاستعلامات تتم مطابقتها بالفعل مع مربعات GT المصدر الخاصة بها ولا تتطلب مطابقة ثنائية الأطراف. أظهر مؤلفو DN-DETR أنه خلال مراحل التحقق من الصحة في نهاية كل حقبة (حيث يتم إيقاف تشغيل إزالة الضوضاء)، فإن ذلك يحسن استقرار النموذج مقارنةً بـ DETR و DAB-DETR، بمعنى أن المزيد من الاستعلامات متسقة في مطابقتها مع كائن GT في الحقب المتتالية. (انظر الشكل 2).
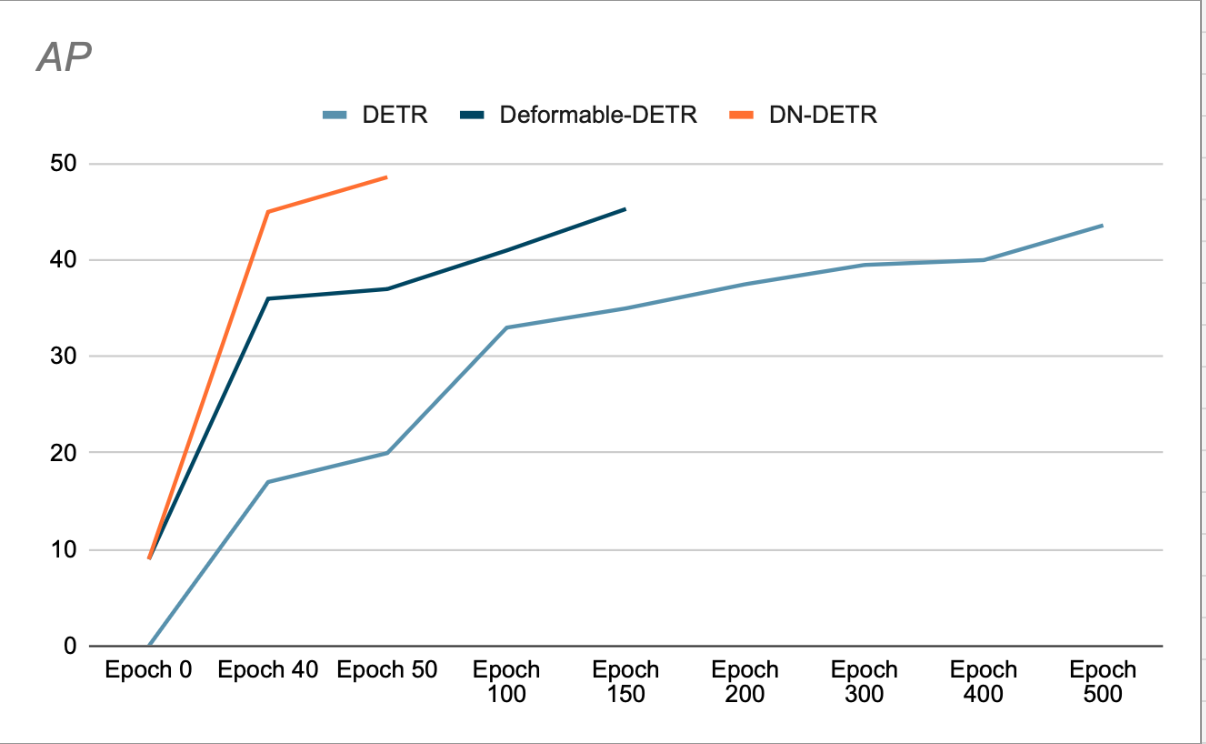
يوضح المؤلفون أن استخدام DN يسرع التقارب ويحقق نتائج كشف أفضل. (انظر الشكل 3). تُظهر دراسة الإزالة الخاصة بهم زيادة بنسبة 1.9% في AP (متوسط الدقة) على مجموعة بيانات كشف COCO، مقارنةً بـ SOTA (DAB-DETR، AP 42.2%) السابقة، عند استخدام ResNet-50 كعمود فقري.
DINO وإزالة الضوضاء التباينية
طوّر DINO هذه الفكرة، وأضاف التعلم التبايني إلى آلية إزالة الضوضاء: بالإضافة إلى المثال الإيجابي، ينشئ DINO نسخة أخرى مشوشة لكل GT، والتي يتم إنشاؤها رياضيًا لتكون أبعد عن GT، مقارنة بالمثال الإيجابي (انظر الشكل 4). يتم استخدام هذه النسخة كمثال سلبي للتدريب: يتعلم النموذج قبول الاكتشاف الأقرب إلى الحقيقة الأساسية، ورفض الاكتشاف الأبعد (عن طريق تعلم التنبؤ بالفئة “لا يوجد كائن”).
بالإضافة إلى ذلك، يمكّن DINO مجموعات متعددة لإزالة الضوضاء التباينية (CDN) – نقاط ارتكاز مشوشة متعددة لكل كائن GT – مما يحقق أقصى استفادة من كل تكرار تدريبي.
أفاد مؤلفو DINO عن متوسط الدقة (AP) بنسبة 49% (على COCO val2017) عند استخدام CDN.
تستخدم النماذج الزمنية الحديثة، التي تحتاج إلى تتبع الكائنات من إطار إلى إطار، مثل Sparse4Dv3، CDN، وتضيف مجموعات إزالة الضوضاء الزمنية، حيث يتم تخزين بعض نقاط ارتكاز DN الناجحة (جنبًا إلى جنب مع نقاط الارتكاز المتعلمة غير DN)، للاستخدام في الإطارات اللاحقة، مما يعزز أداء النموذج في تتبع الكائنات.

مناقشة
يبدو أن إزالة الضوضاء (Denoising (DN)) تحسن سرعة التقارب والأداء النهائي لكواشف الرؤية القائمة على المحولات (vision transformer detectors). ولكن، عند فحص تطور الطرق المختلفة المذكورة أعلاه، تثار الأسئلة التالية:
- تعمل تقنية DN على تحسين النماذج التي تستخدم مثبتات (anchors) قابلة للتعلم. ولكن هل المثبتات القابلة للتعلم مهمة حقًا؟ وهل ستحسن DN أيضًا النماذج التي تستخدم مثبتات غير قابلة للتعلم؟
- تتمثل المساهمة الرئيسية لـ DN في التدريب في إضافة الاستقرار إلى عملية تدرج النزول (gradient descent) عن طريق تجاوز المطابقة الثنائية (bipartite matching). ولكن يبدو أن المطابقة الثنائية موجودة بشكل أساسي لأن المعيار في أعمال المحولات هو تجنب القيود المكانية على الاستعلامات. لذلك، إذا قمنا بتقييد الاستعلامات يدويًا لمواقع صور معينة، وتخلينا عن استخدام المطابقة الثنائية (أو استخدمنا نسخة مبسطة من المطابقة الثنائية، والتي يتم تشغيلها على كل رقعة صورة على حدة) – فهل ستظل DN تحسن النتائج؟
لم أتمكن من العثور على أعمال قدمت إجابات واضحة لهذه الأسئلة. فرضيتي هي أن النموذج الذي يستخدم مثبتات غير قابلة للتعلم (شريطة ألا تكون المثبتات متفرقة جدًا) واستعلامات مقيدة مكانيًا، 1 – لن يتطلب خوارزمية مطابقة ثنائية، و 2 – لن يستفيد من DN في التدريب، حيث أن المثبتات معروفة بالفعل ولا يوجد ربح في تعلم الانحدار من مثبتات زائلة أخرى.
إذا كانت المثبتات ثابتة ولكنها متفرقة، فيمكنني أن أرى كيف أن استخدام مثبتات زائلة يسهل الانحدار منها، ويمكن أن يوفر بداية دافئة لعملية التدريب.
تقارن Anchor-DETR (Wand et al.، 2021) التوزيع المكاني للمثبتات القابلة للتعلم وغير القابلة للتعلم، وأداء النماذج المعنية، وفي رأيي، فإن قابلية التعلم لا تضيف قيمة كبيرة لأداء النموذج. والجدير بالذكر أنهم يستخدمون الخوارزمية الهنغارية في كلتا الطريقتين، لذلك من غير الواضح ما إذا كان بإمكانهم التخلي عن المطابقة الثنائية والاحتفاظ بالأداء.
أحد الاعتبارات التي يجب مراعاتها هو أنه قد تكون هناك أسباب إنتاجية لتجنب NMS في الاستدلال، مما يشجع على استخدام الخوارزمية الهنغارية في التدريب.
أين يمكن أن تكون إزالة الضوضاء ذات أهمية حقًا؟ في رأيي – في التتبع. في التتبع، يتم تزويد النموذج بتدفق فيديو، والمطلوب ليس فقط اكتشاف كائنات متعددة عبر إطارات متتالية، ولكن أيضًا الحفاظ على الهوية الفريدة لكل كائن تم اكتشافه. لا تعالج نماذج المحولات الزمنية (Temporal transformer models)، أي النماذج التي تستخدم الطبيعة التسلسلية لتدفق الفيديو، الإطارات الفردية بشكل مستقل. بدلاً من ذلك، فإنها تحتفظ ببنك يخزن الاكتشافات السابقة. في التدريب، يتم تشجيع نموذج التتبع على الانحدار من اكتشاف الكائن السابق (أو بشكل أكثر دقة – المثبت المرتبط بالاكتشاف السابق للكائن)، بدلاً من الانحدار ببساطة من أقرب مثبت. وبما أن الاكتشاف السابق غير مقيد ببعض شبكة المثبتات الثابتة، فمن المعقول أن تكون المرونة التي تحفزها DN مفيدة. أود بشدة أن أقرأ أعمالًا مستقبلية تهتم بهذه القضايا.
هذا كل شيء عن إزالة الضوضاء ومساهمتها في محولات الرؤية! إذا أعجبك مقالي، فأنت مدعو لزيارة بعض مقالاتي الأخرى حول التعلم العميق والتعلم الآلي و رؤية الحاسوب!
التعليقات مغلقة.