

منذ أن ظهر Gemini 3 لأول مرة، وهو يحافظ بنجاح على مكانته في قمة الـ قائمة المتصدرين في LMArena. هذه القائمة عبارة عن تصنيف جماعي حيث يقارن آلاف المستخدمين الحقيقيين نماذج الذكاء الاصطناعي وجهًا لوجه عبر مجموعة واسعة من المهام، ويصوتون على الاستجابة الأفضل. ولكن عندما يتعلق الأمر بتحقيق أصعب معايير الاستدلال، هناك نجم صاعد جديد، وقد تفوق بالفعل على Google – وفعل ذلك دون تدريب نموذجه الخاص.
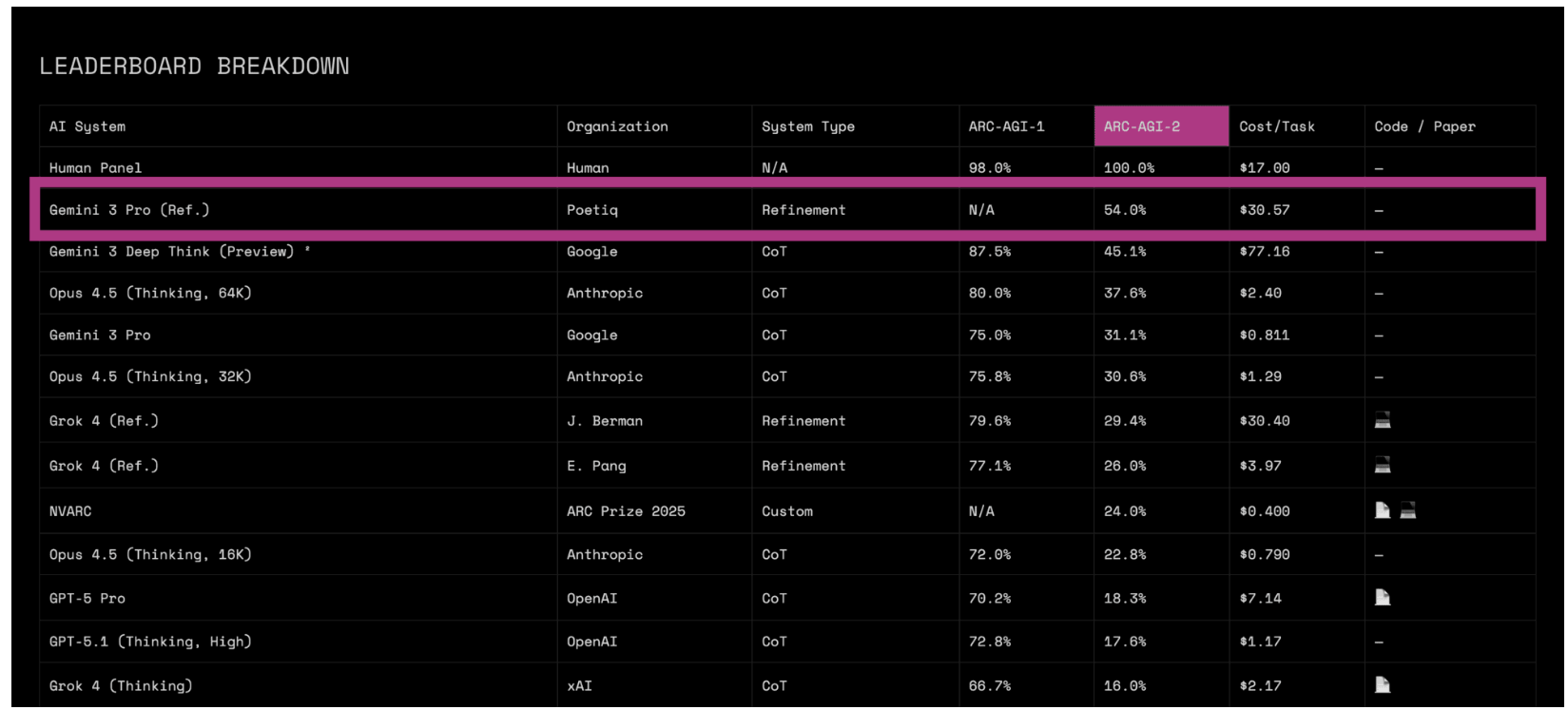
تقول شركة ناشئة مكونة من ستة أشخاص تُعرف باسم Poetiq إنها احتلت المرتبة الأولى في مجموعة اختبار ARC-AGI-2 شبه الخاصة، وهو تحدي استدلال صعب للغاية أنشأه باحث الذكاء الاصطناعي François Chollet. سجل نظام الشركة الناشئة 54 بالمائة، متفوقًا على ما أبلغت عنه Google سابقًا لـ Gemini 3 Deep Think بنحو 45 بالمائة.

ولوضع ذلك في نصابه الصحيح، كانت معظم نماذج الذكاء الاصطناعي عالقة تحت 5 بالمائة في هذا المعيار قبل ستة أشهر فقط. وكان تجاوز 50 بالمائة شيئًا افترض الباحثون على نطاق واسع أنه سيستغرق سنوات.
والجزء الأكثر إثارة للدهشة: لم يكن اختراق Poetiq مدعومًا بنموذج حدودي جديد – ولكن بطريقة أكثر ذكاءً لتنظيم النماذج الحالية.
كيف حققت Poetiq هذا الإنجاز؟
بدلاً من بناء محوّل ضخم من الصفر، طورت Poetiq ما تسميه نظامًا فوقيًا؛ وهو في الأساس وحدة تحكم بالذكاء الاصطناعي تشرف على مخرجات أي نموذج تقوم بتوصيله بها، وتنتقدها وتحسنها. لعملهم ARC-AGI-2، استخدم الفريق Gemini 3 Pro كنموذج أساسي.
تصف Poetiq النظام بأنه حلقة تحسين محكمة: إنشاء > نقد > تحسين > تحقق.
إليكم ما يجعله متميزًا:
- لا يتطلب إعادة تدريب: يتكيف النظام مع النماذج الجديدة في غضون ساعات
- مبني بالكامل على نماذج لغوية كبيرة جاهزة: لا يوجد تعديل مخصص
- تكلفة أقل: يقال إن Deep Think من Google يكلف 77 دولارًا لكل مهمة؛ نظام Poetiq أقرب إلى 30 دولارًا
- مفتوح المصدر: الحل متاح للجمهور وقابل للفحص
- تدقيق ذاتي: يقوم النظام بتقييم إجاباته الخاصة قبل إرجاع النتيجة النهائية
على الموقع الإلكتروني للشركة، يقول فريق Poetiq إن هذا النهج يعمل عن طريق استخلاص المزيد من قوة الاستدلال من النماذج اللغوية الكبيرة الحالية – وليس عن طريق توسيع نطاق الحوسبة بالقوة الغاشمة.
لماذا يعتبر اختبار ARC-AGI-2 مهمًا؟

بينما تقيس معظم الاختبارات المعيارية مهارات محدودة مثل البرمجة أو الرياضيات، تم تصميم ARC-AGI-2 لاختبار شيء أعمق: التعرف على الأنماط، والقياس، والاستدلال المجرد، ونوع التعميم الذي يتعلمه البشر في الطفولة المبكرة.
إنه صعب عن قصد وغير ودود بشكل ملحوظ لنماذج اللغات الكبيرة (LLMs) الحالية. حتى العديد من النماذج المتطورة تفشل فيه بشكل مذهل.
لهذا السبب، فإن القفزة من نتائج ذات رقم واحد إلى 54 بالمائة في نصف عام قد أثارت الدهشة. يشير هذا إلى تقدم في طرق الاستدلال، وليس مجرد حجم النموذج الخام.
ومع ذلك، تنطبق نتيجة Poetiq تحديدًا على مجموعة الاختبار شبه الخاصة، والتي ليست مفتوحة بالكامل للجمهور. يقول موقع الشركة إنه تم التحقق من النتيجة من قبل منظمي الاختبار المعياري – ولكن لا يزال التكرار المستقل من طرف ثالث معلقًا، وهو أمر مهم بالنسبة لاختبار معياري بهذا التأثير.
ربما لن يأتي الاختراق التالي من نماذج أكبر، حيث يسلط عمل Poetiq الضوء على اتجاه متزايد في الذكاء الاصطناعي: التقدم لا يتطلب دائمًا بنية تحتية بمليارات الدولارات أو مختبر أبحاث ضخم.
إذا نجحت أنظمة كهذه في تجاوز المعايير القياسية لتشمل التخطيط، والبرمجة، والأبحاث، أو حتى اتخاذ القرارات في العالم الحقيقي، فقد يعيد ذلك تشكيل طريقة تطوير الذكاء الاصطناعي. فبدلاً من انتظار النموذج الخارق التالي، قد تتجه الشركات إلى بناء ذكاء مُركّب يجعل نماذج اليوم أكثر ذكاءً، وأقل تكلفة، وأكثر اتساقًا.
الخلاصة
أصدرت Poetiq حلاً مفتوح المصدر لـ ARC-AGI ليتمكن الباحثون من اختباره، وتوسيعه، أو حتى تحدي نتائجه. يحتوي المعيار القياسي على مجموعة اختبار مخفية، والتاريخ يظهر أن النتائج يمكن أن تتغير بمجرد أن يقوم المزيد من الأشخاص بإجراء تقييمات مستقلة.
إذا صمدت أرقام Poetiq، فقد يمثل ذلك نقطة تحول في أبحاث الاستدلال في الذكاء الاصطناعي. فقد يكون فريق مكون من ستة أشخاص قد أظهر للتو أن تنسيق النماذج يمكن أن ينافس، أو حتى يتفوق على، تدريب نماذج أكبر. أثبتت Poetiq للتو أنك لست بحاجة إلى مختبر عملاق لتحقيق الفوز.
التعليقات مغلقة.