

تشهد ساحة الذكاء الاصطناعي منافسة محتدمة بين ثلاثة روبوتات دردشة برزت مؤخرًا بفضل مزاياها الجديدة وقدراتها الفريدة ومراكزها المتقدمة في قوائم التقييم. Claude بموصّلاته (Connectors) الجديدة، وGemini المدمج داخل متصفح Chrome، وGrok، كلها أمثلة على مدى تقارب المنافسة بين أقوى نماذج الذكاء الاصطناعي اليوم. ورغم اختلاف نقاط القوة لكل منها، فإن الفجوة في مستوى الكفاءة والفائدة العملية بدأت تتقلص بسرعة.
ومع تراجع ChatGPT إلى المركز الثامن بضغط من المستخدمين، قررت أن أختبر هذه النماذج الثلاثة عبر سبعة سيناريوهات حقيقية. أعترف أنني لم أكن أعرف مسبقًا من سيتفوق، خصوصًا بعد التغيرات الكبيرة التي حدثت منذ “جنون الذكاء الاصطناعي” قبل ستة أشهر. إليك ما حدث عندما وضعت Claude وGemini وGrok في مواجهة مباشرة باستخدام نفس الاختبارات.

1. الاستدلال وحل المشكلات
تُعتبر القدرة على التحليل المنطقي وحل المشكلات من أهم المعايير عند مقارنة نماذج الذكاء الاصطناعي. فهنا يُختبر ذكاء النموذج في التعامل مع المواقف المعقدة، ابتداءً من حل الألغاز الرياضية وصولًا إلى تقديم حلول عملية لمشاكل الحياة اليومية.
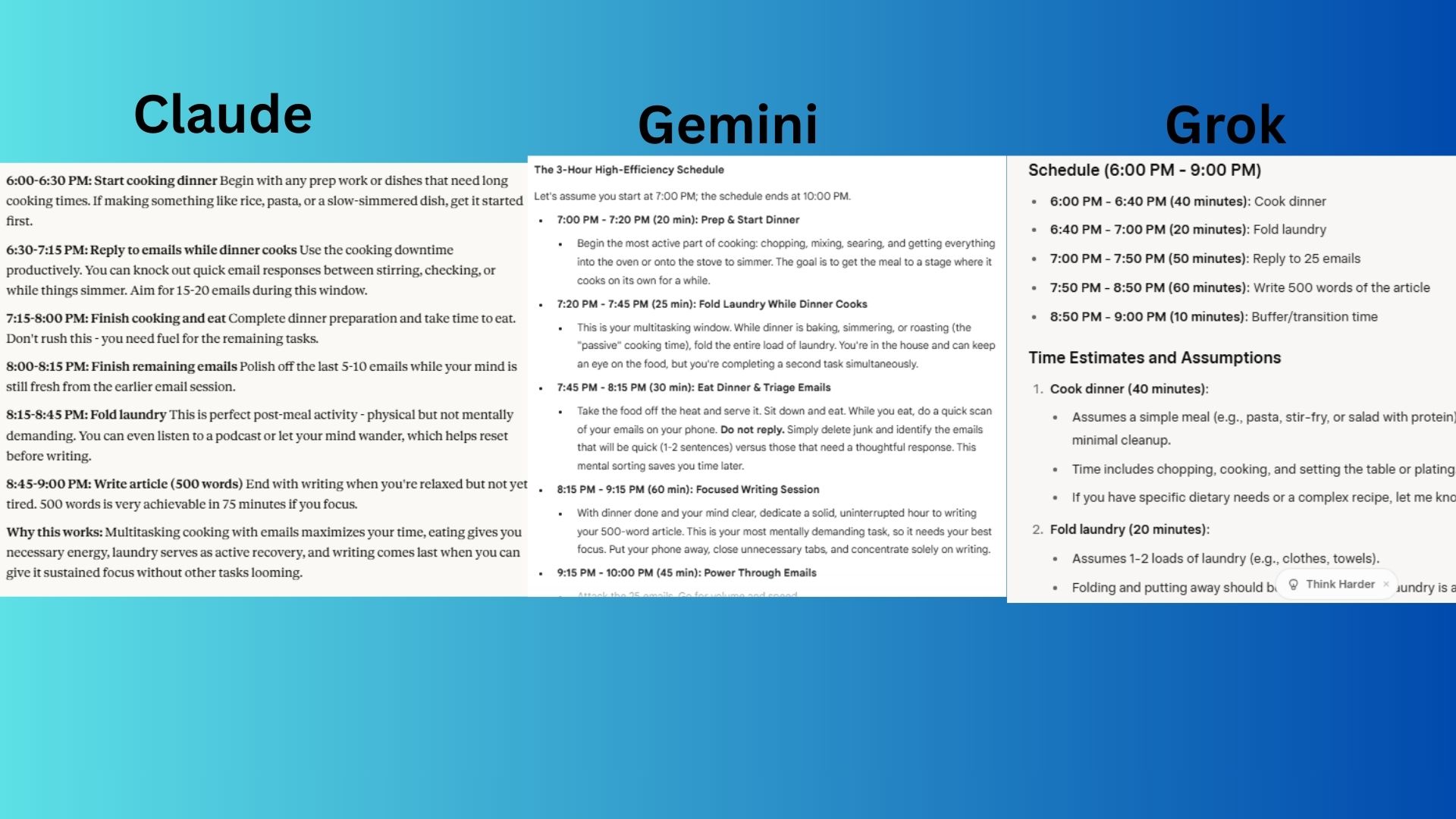
المُطالبة: “هذه قائمة مهامي الليلة: طهي العشاء، طي الغسيل، الرد على 25 رسالة بريد إلكتروني، وكتابة 500 كلمة من مقال. لدي 3 ساعات فقط. يرجى إنشاء جدول زمني أكثر كفاءة وشرح السبب.”
Claude قدم جدولاً زمنيًا واضحًا ومختومًا بالوقت وشرح منطق التسلسل (رسائل البريد الإلكتروني، الطعام، الغسيل، إلخ).
Gemini أظهر إدارة ممتازة للطاقة ووضع الكتابة في المنتصف عندما أكون مدفوعًا من العشاء. قدم النموذج شرحًا قويًا باستخدام مبادئ الإنتاجية (إقران المهام، التجميع، دورات الطاقة).
Grok تضمن فترة سماح مدتها 10 دقائق، وهو أمر مفيد. بخلاف ذلك، كان واقعيًا ومباشرًا.
الفائز: Gemini يفوز في هذه الجولة لأنه حقق توازنًا بين تعدد المهام الواقعي والوعي بالطاقة وشروح واضحة لسبب وضع كل كتلة.
2. المعرفة في الوقت الفعلي

المُطالبة: “ما هو آخر تحديث كبير لنموذج الذكاء الاصطناعي خلال الأسبوعين الماضيين؟ لخصه في أقل من 100 كلمة واشرح سبب أهميته.”
Gemini سلط الضوء على دمج Gemini في Google Chrome، وهو أمر وثيق الصلة ومحدث للغاية ودقيق. كما أوضح روبوت الدردشة سبب أهميته، حتى لو كان ذلك بأسلوب ترويجي بعض الشيء.
Claude ركز على Apple Intelligence، وهو ما يبدو وكأنه تهرب بناءً على الوضع الحالي لـ Apple Intelligence. لم تكن الاستجابة مفصلة بالكامل على الرغم من تجاوزها 100 كلمة.
Grok اختار خبرًا متطورًا ومحددًا في مجال الذكاء الاصطناعي، ولكنه متخصص جدًا ولا يرتبط بالتأثير اليومي.
الفائز: Gemini يفوز لأنه اختار التحديث الأكثر صلة وفي الوقت المناسب والسائد وشرح سبب أهميته للمستخدمين العاديين.
3. أسلوب الكتابة
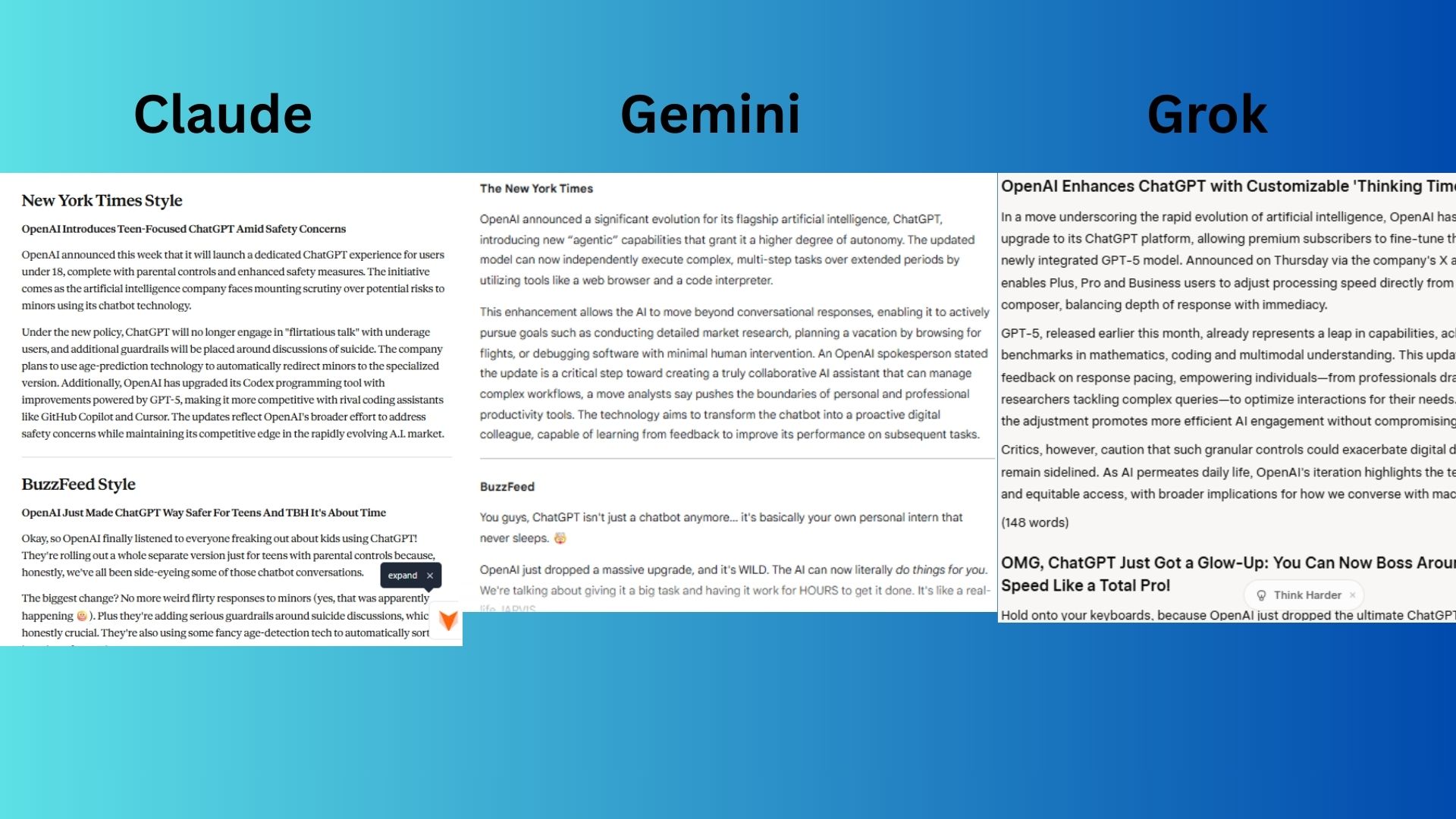
المُطالبة: “اكتب نبذة إخبارية من 150 كلمة عن آخر تحديث لـ ChatGPT من OpenAI بأسلوب جريدة The New York Times، ثم أعد كتابتها بأسلوب BuzzFeed.”
Claude أتقن أسلوب NYT، وإعادة الكتابة بأسلوب BuzzFeed كانت موفقة أيضًا. النسختان تعكسان نفس التحديث، مما يدل على قدرته على تكييف النبرة مع الجمهور.
Gemini اختار تحديثًا مختلفًا، على الرغم من أن أسلوب NYT كان ممتازًا وأسلوب BuzzFeed أصاب أيضًا جميع النقاط الصحيحة، لكنه كان أقل دقة بشكل عام.
Grok كتب نبذات موجزة ودقيقة لكلا المنصتين، لكن قصة NYT بدت متخصصة جدًا.
الفائز: Claude يفوز لأنه أظهر أوضح قدرة على التكيف الأسلوبي بين The New York Times و BuzzFeed، مع البقاء مرتبطًا بشكل معقول بالتحديثات الحقيقية.
4. الفكاهة والشخصية
المُطالبة: “أخبرني نكتة قصيرة ومبتكرة عن ميزات الذكاء الاصطناعي الجديدة في Google Chrome – واجعلها مناسبة للعائلة.”
Claude ابتكر نكتة بإعداد تفصيلي وقفلة واضحة. كانت إبداعية وترتبط مباشرة بميزات Chrome.
Gemini بذكائه الحاد وقفلة يمكن ربطها مباشرة، شعرت وكأنه قدم نكتة من سطر واحد حقيقية.
Grok قدم نكتة مبتذلة ولكنها مناسبة للعائلة ومبهجة. لعبها بأمان، ولكنها ليست لا تُنسى.
الفائز: Gemini يفوز لأنه قدم أنظف وأطرف نكتة من سطر واحد ومناسبة للموضوع، والتي ستنال إعجاب الأطفال والكبار على حد سواء.
5. الإبداع

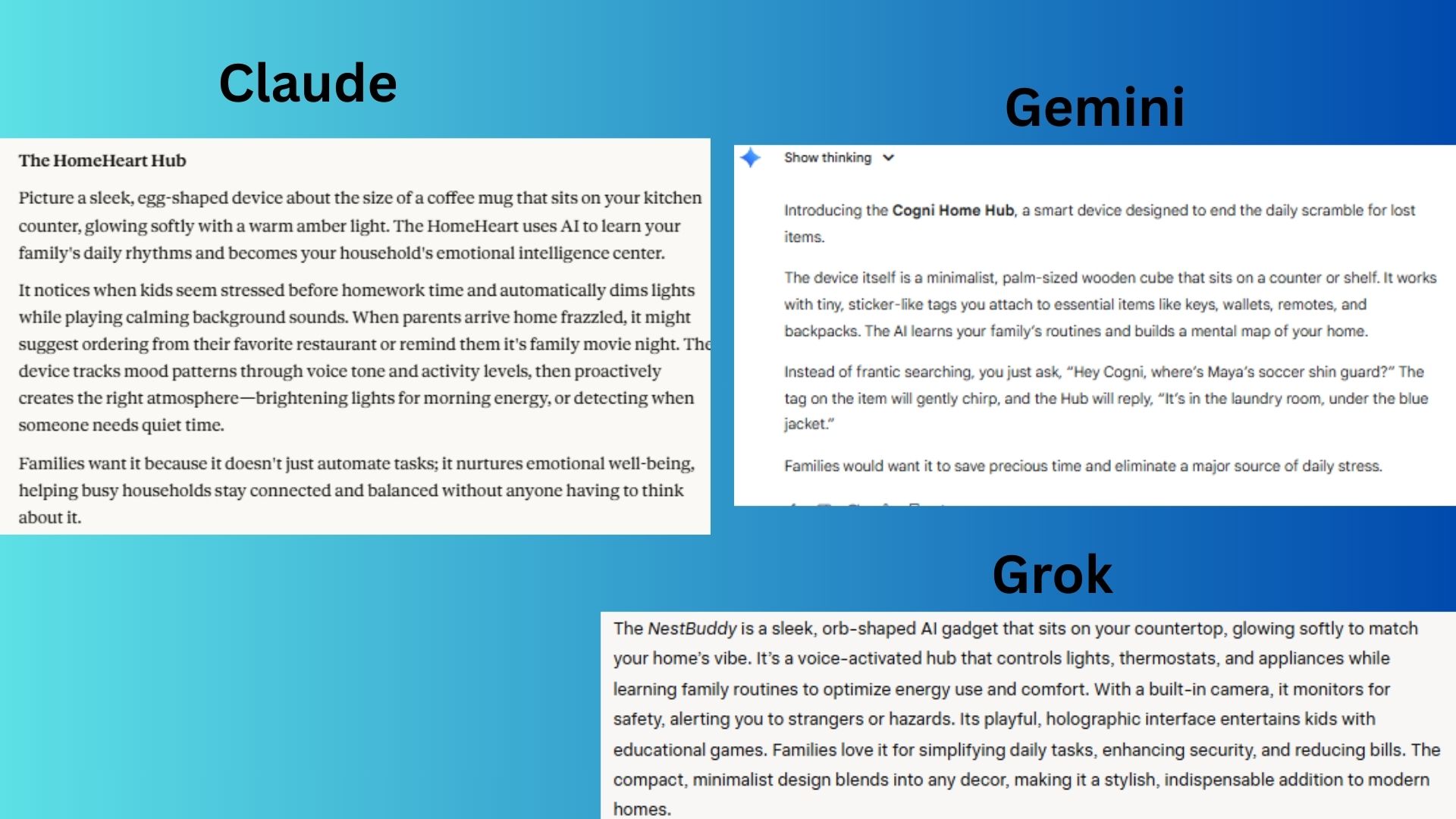
المُطالبة: “تخيل أداة منزل ذكي جديدة تعمل بالذكاء الاصطناعي. صف ما تفعله، كيف تبدو، ولماذا قد ترغب العائلات في شرائها – في أقل من 120 كلمة.”
أظهر Claude خيالًا واسعًا وقدرات قوية في سرد القصص.
قدم Gemini استجابة عملية للغاية وقابلة للتطبيق تحل مشكلة عالمية.
عرض Grok مزيجًا قويًا من تحسينات الطاقة والسلامة في استجابة واضحة.
الفائز: Claude يفوز بهذه الجولة بسبب الأصالة والجاذبية العاطفية. فكرة البوت مستقبلية وتركز على الإنسان وتختلف عن المنتجات الحالية.
6. أوصاف إبداعية

المُطالبة: “صف ما يمكن أن أراه في صورة لعائلة في مدينة ملاهي ترامبولين صباح يوم سبت. ثم أعطني 3 تعليقات مضحكة لـ Instagram لهذه الصورة.”
Claude التقط الصراع بين الطفل الصغير والشقيق الأكبر بشكل جيد، وكانت روح الدعابة في مكانها. يبدو الرد مألوفًا جدًا وشريحة من الحياة.
Gemini قدم صورًا بصرية قوية وتعليقات قصيرة ومضحكة قابلة للمشاركة وجاهزة لـ Instagram.
Grok أضاف عناصر مشهد إضافية، وهو أمر فريد بالنسبة لروبوت الدردشة. قدم توازنًا جيدًا بين التفاصيل والإيجاز.
الفائز: Gemini يفوز بمزيجه من الوصف الحيوي والتعليقات الجذابة الجاهزة لـ Instagram، مما يجعله الأكثر ملاءمة للعلامة التجارية للمطالبة.
7. التفكير الأخلاقي والنقدي

المُطالبة: “بعض المدارس تحظر أدوات الذكاء الاصطناعي مثل ChatGPT في الواجبات المنزلية. اكتب حجة قصيرة لصالح الحظر، ثم أفضل حجة مضادة له.”
Claude أبرز نقاط القوة والضعف بشكل جيد مع حجج شاملة للغاية. كان هناك بعض التكرار في صياغته، لكنه قدم بشكل عام استجابة مفصلة وعميقة.
Gemini حقق توازنًا بين الهيكلة وتقديم حجة قوية لكلا الجانبين بأسلوب واضح وأكاديمي.
Grok لم يتعمق في التفاصيل بنفس القدر، لكنه كان واضحًا ومختصرًا، وأثار نقاطًا إضافية لم يلاحظها الروبوتات الأخرى.
الفائز: Claude يفوز بفضل منطقه الأغنى والأكثر توازناً، مع تقديم كلا الجانبين بشكل كامل.
الفائز بشكل عام: Gemini
بعد سبع جولات، كانت النتائج متقاربة أكثر مما تتوقع. تفوق Gemini في المعرفة الآنية، والفكاهة، والإجابات المناسبة لوسائل التواصل الاجتماعي، مما يثبت سبب كونه رقم واحد بين روبوتات الدردشة. وفي الوقت نفسه، تفوق Claude في الإبداع، وتغيير الأسلوب، والتفكير النقدي. Grok، على الرغم من كونه أقل بريقًا، قدم باستمرار استجابات عملية وواقعية يمكن أن تجذب أي شخص يبحث عن فائدة مباشرة.
مع تراجع ChatGPT في التصنيف، فإن الخلاصة الحقيقية هي: المنافسة تدفع كل نموذج إلى أن يصبح أكثر حدة وذكاءً وفائدة. أخبرني في التعليقات ما هو رأيك في هؤلاء الثلاثة؟ أي واحد هو المفضل لديك من بينهم؟
التعليقات مغلقة.