

تقييم أداء نماذج DeepSeek-R1 المقطرة على GPQA باستخدام Ollama و simple-evals من OpenAI
قم بإعداد وتشغيل اختبار GPQA-Diamond المعياري على نماذج DeepSeek-R1 المقطرة محليًا لتقييم قدرات الاستدلال الخاصة بها.
أحدث إطلاق لنموذج DeepSeek-R1 صدى واسعًا في مجتمع الذكاء الاصطناعي العالمي. لقد حقق اختراقات تضاهي نماذج الاستدلال من Meta و OpenAI، وحقق ذلك في جزء صغير من الوقت وبتكلفة أقل بكثير.
ولكن بعيدًا عن العناوين الرئيسية والضجة الإعلامية عبر الإنترنت، كيف يمكننا تقييم قدرات الاستدلال في النموذج باستخدام معايير معترف بها؟ هذا سؤال مهم لخبراء الذكاء الاصطناعي.
واجهة المستخدم الخاصة بـ Deepseek تجعل من السهل استكشاف قدراتها، ولكن استخدامها برمجيًا يوفر رؤى أعمق وتكاملًا أكثر سلاسة في التطبيقات الواقعية. إن فهم كيفية تشغيل هذه النماذج محليًا يوفر أيضًا تحكمًا محسنًا ووصولاً دون اتصال بالإنترنت.

في هذه المقالة، سوف نستكشف كيفية استخدام Ollama و simple-evals من OpenAI لتقييم قدرات الاستدلال لنماذج DeepSeek-R1 المقطرة بناءً على معيار GPQA-Diamond الشهير. يعتبر هذا المعيار من أهم الأدوات لتقييم نماذج الذكاء الاصطناعي في مجال الاستدلال المنطقي.
إليك رابط مستودع GitHub المصاحب لهذه المقالة.
(1) ما هي نماذج الاستدلال؟
نماذج الاستدلال، مثل DeepSeek-R1 ونماذج السلسلة o من OpenAI (مثل o1، o3)، هي نماذج لغوية كبيرة (LLMs) تم تدريبها باستخدام التعلم المعزز لأداء الاستدلال. تعتبر هذه النماذج أدوات متطورة في مجال الذكاء الاصطناعي، حيث تمثل قمة التطور في قدرة الآلات على التفكير المنطقي وحل المشكلات المعقدة.
تتميز نماذج الاستدلال بالتفكير العميق قبل الإجابة، حيث تنتج سلسلة طويلة من الأفكار الداخلية قبل الاستجابة. إنها تتفوق في حل المشكلات المعقدة، والبرمجة، والاستدلال العلمي، والتخطيط متعدد الخطوات لسير عمل الوكلاء. هذه القدرات تجعلها لا غنى عنها في مجالات مثل تطوير البرمجيات المتقدمة، والبحث العلمي، وأتمتة العمليات المعقدة.
(2) ما هو نموذج DeepSeek-R1؟
DeepSeek-R1 هو نموذج لغوي كبير مفتوح المصدر (LLM) يعتبر الأحدث في المجال، ومصمم خصيصًا لـ الاستدلال المتقدم. تم تقديمه في يناير 2025 في الورقة البحثية “DeepSeek-R1: تحفيز قدرة الاستدلال في النماذج اللغوية الكبيرة عبر التعلم المعزز“. يعتبر DeepSeek-R1 نموذجًا رائدًا في مجال الذكاء الاصطناعي.
يعتمد هذا النموذج على معمارية نموذج لغوي كبير (LLM) بـ 671 مليار معلمة، وتم تدريبه باستخدام مكثف للتعلم المعزز (RL) بناءً على المسار التالي:
- مرحلتان من التعزيز تهدفان إلى اكتشاف أنماط استدلال محسنة والتوافق مع التفضيلات البشرية.
- مرحلتان من الضبط الدقيق الخاضع للإشراف تعملان كبذرة لقدرات النموذج في الاستدلال وغير الاستدلال.
لتوضيح الأمر، قامت DeepSeek بتدريب نموذجين:
- النموذج الأول، DeepSeek-R1-Zero، هو نموذج استدلال تم تدريبه باستخدام التعلم المعزز، ويقوم بإنشاء بيانات لتدريب النموذج الثاني، DeepSeek-R1.
- يحقق ذلك من خلال إنتاج آثار استدلال، يتم الاحتفاظ فقط بالمخرجات عالية الجودة منها بناءً على نتائجها النهائية.
- هذا يعني أنه على عكس معظم النماذج، فإن أمثلة التعلم المعزز (RL) في مسار التدريب هذا لا يتم تنسيقها بواسطة البشر ولكن يتم إنشاؤها بواسطة النموذج نفسه.
النتيجة هي أن النموذج حقق أداءً مماثلاً للنماذج الرائدة مثل نموذج o1 من OpenAI في مهام مثل الرياضيات والبرمجة والاستدلال المعقد.
(3) فهم عملية التقطير والنماذج المُقطرة من DeepSeek-R1
بالإضافة إلى النموذج الكامل، قاموا أيضًا بفتح مصدر ستة نماذج كثيفة أصغر حجمًا (تسمى أيضًا DeepSeek-R1) بأحجام مختلفة (1.5B، 7B، 8B، 14B، 32B، 70B)، تم تقطيرها من DeepSeek-R1 استنادًا إلى Qwen أو Llama كالنموذج الأساسي.
التقطير (Distillation) هو تقنية يتم فيها تدريب نموذج أصغر (“الطالب”) لتكرار أداء نموذج أكبر وأكثر قوة تم تدريبه مسبقًا (“المعلم”).
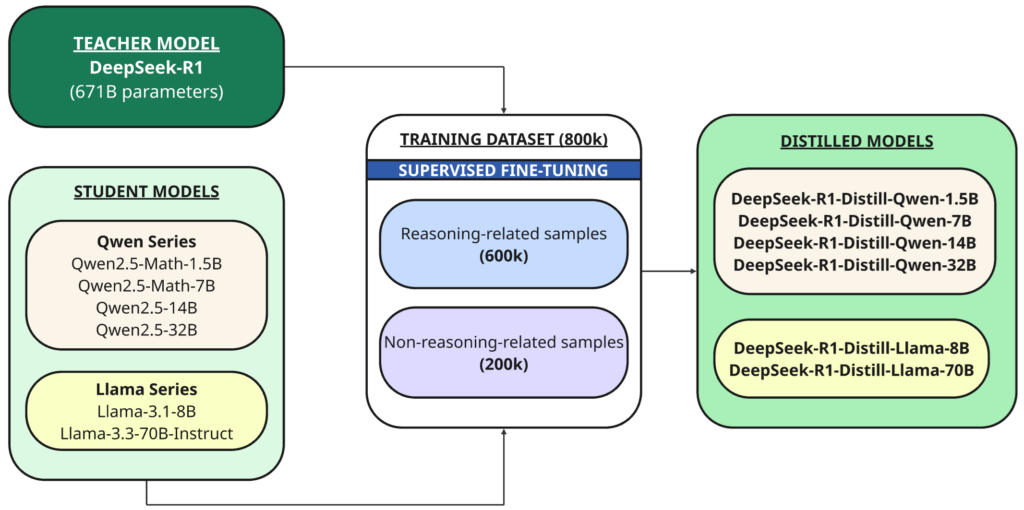
في هذه الحالة، المُعلم هو نموذج DeepSeek-R1 بحجم 671B، والطلاب هم النماذج الستة التي تم تقطيرها باستخدام هذا النموذج الأساسي مفتوح المصدر:
- Qwen2.5 — Math-1.5B
- Qwen2.5 — Math-7B
- Qwen2.5 — 14B
- Qwen2.5 — 32B
- Llama-3.1 — 8B
- Llama-3.3 — 70B-Instruct
تم استخدام DeepSeek-R1 كنموذج معلم لإنشاء 800,000 عينة تدريب، وهي مزيج من عينات الاستدلال وغير الاستدلال، للتقطير عبر الضبط الدقيق الخاضع للإشراف (supervised fine-tuning) للنماذج الأساسية (1.5B، 7B، 8B، 14B، 32B، و 70B).
إذًا، لماذا نقوم بالتقطير في المقام الأول؟
الهدف هو نقل قدرات الاستدلال للنماذج الأكبر، مثل DeepSeek-R1 671B، إلى نماذج أصغر وأكثر كفاءة. وهذا يمكّن النماذج الأصغر من التعامل مع مهام الاستدلال المعقدة مع كونها أسرع وأكثر كفاءة في استخدام الموارد.
علاوة على ذلك، يحتوي DeepSeek-R1 على عدد هائل من المعلمات (671 مليار)، مما يجعل تشغيله أمرًا صعبًا على معظم الأجهزة الاستهلاكية.
حتى أقوى جهاز MacBook Pro، بذاكرة موحدة قصوى تبلغ 128GB، غير كافٍ لتشغيل نموذج بمعلمات تبلغ 671 مليار.
على هذا النحو، تفتح النماذج المقطرة إمكانية نشرها على الأجهزة ذات الموارد الحسابية المحدودة.
حققت Unsloth إنجازًا باهرًا عن طريق تكميم نموذج DeepSeek-R1 الأصلي ذي الـ 671 مليار معلمة إلى 131 جيجابايت فقط – وهو تخفيض ملحوظ بنسبة 80% في الحجم. ومع ذلك، يظل متطلب ذاكرة الوصول العشوائي (VRAM) بسعة 131 جيجابايت يشكل عائقًا كبيرًا، خاصة للمطورين الذين يعملون على أجهزة ذات موارد محدودة. هذا الإنجاز يمثل خطوة هامة نحو جعل نماذج الذكاء الاصطناعي الكبيرة في متناول شريحة أوسع من المستخدمين.
(4) اختيار النموذج المُقطَّر الأمثل
مع توفر ستة أحجام مختلفة للنماذج المُقطَّرة للاختيار من بينها، يعتمد تحديد النموذج المناسب إلى حد كبير على قدرات الأجهزة المحلية.
بالنسبة لأولئك الذين يمتلكون وحدات معالجة رسومية (GPUs) أو وحدات معالجة مركزية (CPUs) عالية الأداء ويحتاجون إلى أقصى قدر من الأداء، تُعد نماذج DeepSeek-R1 الأكبر (32B وما فوق) مثالية – حتى الإصدار الكمي 671B يعتبر قابلاً للتطبيق.
ومع ذلك، إذا كانت الموارد محدودة أو كنت تفضل أوقات إنشاء أسرع (كما هو الحال بالنسبة لي)، فإن المتغيرات المُقطَّرة الأصغر، مثل 8B أو 14B، تعتبر خيارًا أفضل. هذا يوازن بين الأداء ومتطلبات الموارد.
لهذا المشروع، سأستخدم نموذج DeepSeek-R1 المُقطَّر Qwen-14B، والذي يتوافق مع قيود الأجهزة التي واجهتها. هذا النموذج (14B) يمثل حلاً وسطًا ممتازًا بين الدقة والسرعة، مما يجعله مناسبًا تمامًا لبيئة التطوير الخاصة بي.
(5) معايير تقييم القدرة على الاستدلال لدى نماذج اللغات الكبيرة
عادةً ما يتم تقييم نماذج اللغات الكبيرة (LLMs) باستخدام معايير قياسية تحدد مستوى أدائها في مهام متنوعة، بما في ذلك فهم اللغة، وتوليد التعليمات البرمجية، واتباع التعليمات، والإجابة على الأسئلة. تتضمن الأمثلة الشائعة مقاييس مثل MMLU، و HumanEval، و MGSM. تعتبر هذه المقاييس أساسية في تقييم قدرات نماذج اللغات الكبيرة.
لقياس قدرة نموذج لغوي كبير على الاستدلال المنطقي، نحتاج إلى معايير أكثر تحديًا وتركز بشكل كبير على الاستدلال، وتتجاوز المهام السطحية. فيما يلي بعض الأمثلة الشائعة التي تركز على تقييم قدرات الاستدلال المتقدمة:
(i) امتحان AIME 2024: الرياضيات التنافسية
- يُعد امتحان الدعوة الأمريكي للرياضيات (AIME) 2024 معيارًا قويًا لتقييم قدرات النماذج اللغوية الكبيرة (LLM) في الاستدلال الرياضي.
- يمثل هذا الامتحان تحديًا كبيرًا في مجال الرياضيات التنافسية، حيث يطرح مسائل معقدة ومتعددة الخطوات. يختبر الامتحان قدرة النماذج اللغوية الكبيرة على فهم الأسئلة المعقدة، وتطبيق الاستدلال المتقدم، وإجراء عمليات التلاعب الرمزي الدقيقة. يعتبر AIME مقياسًا هامًا لتقييم مهارات حل المشكلات الرياضية المعقدة.
(ii) Codeforces – كود المنافسة
- يقوم معيار Codeforces بتقييم قدرة نموذج اللغة الكبير (LLM) على الاستنتاج باستخدام مسائل برمجة تنافسية حقيقية من Codeforces، وهي منصة معروفة بتحديات الخوارزميات. يعتبر Codeforces معيارًا ذهبيًا لتقييم قدرات نماذج الذكاء الاصطناعي في حل المشكلات المعقدة.
- تختبر هذه المشكلات قدرة نموذج اللغة الكبير (LLM) على فهم التعليمات المعقدة، وإجراء الاستدلال المنطقي والرياضي، وتخطيط حلول متعددة الخطوات، وإنشاء تعليمات برمجية صحيحة وفعالة. تتطلب هذه المسائل فهمًا عميقًا للخوارزميات وهياكل البيانات، بالإضافة إلى القدرة على ترجمة المشكلة إلى كود قابل للتنفيذ.
(iii) GPQA Diamond – أسئلة علمية بمستوى الدكتوراه
- GPQA-Diamond هي مجموعة فرعية مُنتقاة من أصعب الأسئلة من معيار GPQA (إجابة أسئلة الفيزياء على مستوى الدراسات العليا) الأوسع، وهي مُصممة خصيصًا لتوسيع حدود قدرة نماذج LLM على الاستنتاج في موضوعات متقدمة بمستوى الدكتوراه. يعتبر هذا المعيار تحديًا حقيقيًا لقدرات الذكاء الاصطناعي في فهم واستنتاج المفاهيم العلمية المعقدة.
- بينما يشتمل GPQA على مجموعة من أسئلة الدراسات العليا المفاهيمية والتي تعتمد على العمليات الحسابية، فإن GPQA-Diamond يعزل فقط الأسئلة الأكثر تحديًا وتلك التي تتطلب استنتاجًا مكثفًا.
- يعتبر هذا المعيار “مقاومًا لـ Google”، مما يعني أنه من الصعب الإجابة عليه حتى مع الوصول غير المقيد إلى الويب. وهذا يجعله أداة قيمة لتقييم قدرة النماذج اللغوية الكبيرة على التفكير بشكل مستقل.
- فيما يلي مثال على سؤال GPQA-Diamond:
### GPQA Diamond - Example Question (Molecular Biology) A eukaryotic cell evolved a mechanism to turn macromolecular building blocks into energy. The process occurs in mitochondria, which are cellular energy factories. In the series of redox reactions, the energy from food is stored between the phosphate groups and used as a universal cellular currency. The energy-laden molecules are shuttled out of the mitochondrion to serve in all cellular processes. You discovered a new anti-diabetes drug and want to investigate whether it has an effect on the mitochondria. You set up a range of experiments with your HEK293 cell line. Which of the experiments listed below will not help you discover the mitochondrial role of your drug: (A) Differential centrifugation extraction of mitochondria followed by the Glucose Uptake Colorimetric Assay Kit (B) Flow cytometry after labeling with 2.5 µM 5,5',6,6'-Tetrachloro-1,1',3,3'-tetraethylbenzimidazolylcarbocyanine iodide (C) Transformation of cells with recombinant luciferase and luminometer reading after 5 µM of luciferin addition to the supernatant (D) Confocal fluorescence microscopy after Mito-RTP staining of the cells
في هذا المشروع، نستخدم GPQA-Diamond كمعيار للاستنتاج، كما استخدمته OpenAI و DeepSeek لتقييم نماذج الاستنتاج الخاصة بهما. يعتبر اختيار GPQA-Diamond كمعيار تقييم دليلًا على صعوبته وأهميته في مجال تطوير الذكاء الاصطناعي.
(6) الأدوات المستخدمة
في هذا المشروع، نستخدم بشكل أساسي Ollama و simple-evals من OpenAI. يعتبر Ollama منصة قوية لتشغيل النماذج اللغوية الكبيرة محليًا، بينما توفر simple-evals إطار عمل لتقييم أداء هذه النماذج.
(i) أولاما (Ollama)
Ollama هي أداة مفتوحة المصدر تعمل على تبسيط تشغيل نماذج اللغات الكبيرة (LLMs) على جهاز الكمبيوتر الخاص بنا أو على خادم محلي. تعتبر أولاما منصة مثالية لتشغيل نماذج الذكاء الاصطناعي محليًا.
تعمل كمدير ووقت تشغيل، وتتعامل مع مهام مثل التنزيلات وإعداد البيئة. يتيح ذلك للمستخدمين التفاعل مع هذه النماذج دون الحاجة إلى اتصال دائم بالإنترنت أو الاعتماد على الخدمات السحابية. تعتبر إدارة نماذج اللغات الكبيرة (LLMs) المحلية ميزة أساسية في أولاما.
تدعم العديد من نماذج اللغات الكبيرة مفتوحة المصدر، بما في ذلك DeepSeek-R1، وهي متوافقة عبر الأنظمة الأساسية مع macOS و Windows و Linux. بالإضافة إلى ذلك، فهي توفر إعدادًا مباشرًا بأقل قدر من الضجة واستخدامًا فعالًا للموارد. يتيح لك برنامج أولاما (Ollama) الاستفادة من قوة الذكاء الاصطناعي مباشرة على جهازك.
هام: تأكد من أن جهازك المحلي لديه إمكانية الوصول إلى وحدة معالجة الرسومات (GPU) لـ Ollama، حيث أن ذلك يسرع الأداء بشكل كبير ويجعل عمليات القياس اللاحقة أكثر كفاءة مقارنة بوحدة المعالجة المركزية (CPU). قم بتشغيل الأمر
nvidia-smiفي الطرفية للتحقق مما إذا تم الكشف عن وحدة معالجة الرسومات. هذا الإجراء يضمن الاستفادة القصوى من قدرات الجهاز لتشغيل النماذج بكفاءة عالية.
(ii) مكتبة OpenAI simple-evals لتقييم نماذج اللغة
تُعد simple-evals مكتبة خفيفة الوزن مصممة لتقييم نماذج اللغة باستخدام منهجية التقييم الصفري الفوري (zero-shot) مع تقنية “سلسلة الأفكار” (chain-of-thought prompting). تتضمن هذه المكتبة معايير تقييم مشهورة مثل MMLU و MATH و GPQA و MGSM و HumanEval، وتهدف إلى محاكاة سيناريوهات الاستخدام الواقعية لتقييم أداء نماذج الذكاء الاصطناعي في مهام الاستدلال المعقدة.
قد يكون بعضكم على دراية بمكتبة التقييم الأشهر والأكثر شمولاً من OpenAI والتي تسمى Evals، وهي تختلف عن simple-evals.
في الواقع، تشير صفحة README الخاصة بـ simple-evals تحديدًا إلى أنها ليست مخصصة لاستبدال مكتبة Evals.
إذًا، لماذا نستخدم simple-evals؟
الإجابة البسيطة هي أن simple-evals تأتي مع نصوص تقييم مدمجة لمعايير الاستدلال التي نستهدفها (مثل GPQA)، والتي تفتقدها مكتبة Evals.
بالإضافة إلى ذلك، لم أجد أي أدوات أو منصات أخرى، بخلاف simple-evals، توفر طريقة مباشرة وأصلية بلغة Python لتشغيل العديد من المعايير الرئيسية، مثل GPQA، خاصةً عند العمل مع Ollama.
(7) نتائج التقييم
كجزء من التقييم، قمت باختيار 20 سؤالًا عشوائيًا من مجموعة أسئلة GPQA-Diamond التي تضم 198 سؤالًا ليعمل عليها نموذج 14B المقطر. استغرق الأمر إجمالي 216 دقيقة، أي ما يقرب من 11 دقيقة لكل سؤال.
كانت النتيجة مخيبة للآمال إلى حد ما، حيث سجلت 10% فقط، وهو أقل بكثير من النتيجة المبلغ عنها البالغة 73.3% لنموذج DeepSeek-R1 بحجم 671B.
المشكلة الرئيسية التي لاحظتها هي أنه خلال الاستدلال الداخلي المكثف، غالبًا ما فشل النموذج إما في إنتاج أي إجابة (على سبيل المثال، إرجاع رموز الاستدلال كسطور نهائية للإخراج) أو قدم استجابة لم تتطابق مع تنسيق الاختيار من متعدد المتوقع (على سبيل المثال، الإجابة: أ).
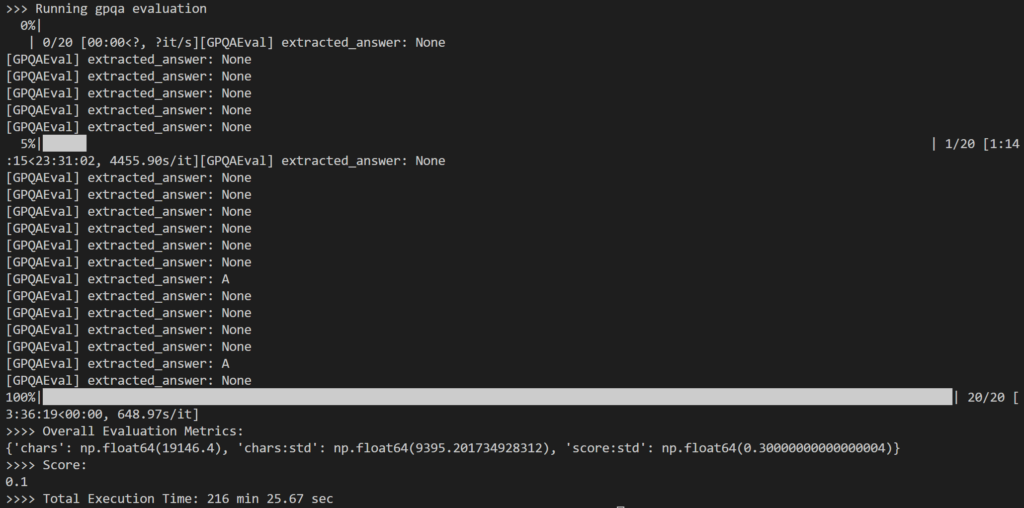
كما هو موضح أعلاه، انتهى الأمر بالعديد من المخرجات كـ None لأن منطق regex في simple-evals لم يتمكن من اكتشاف نمط الإجابة المتوقع في استجابة LLM.
في حين أن منطق الاستدلال الشبيه بالبشر كان مثيرًا للاهتمام للمراقبة، فقد توقعت أداءً أقوى من حيث دقة الإجابة على الأسئلة.
لقد رأيت أيضًا مستخدمين عبر الإنترنت يذكرون أنه حتى نموذج 32B الأكبر لا يعمل بشكل جيد مثل o1. وقد أثار هذا شكوكًا حول فائدة نماذج الاستدلال المقطرة، خاصة عندما تكافح لتقديم إجابات صحيحة على الرغم من توليد استدلال طويل.
ومع ذلك، فإن GPQA-Diamond هو معيار صعب للغاية، لذلك قد تظل هذه النماذج مفيدة لمهام الاستدلال الأبسط. كما أن متطلباتها الحسابية الأقل تجعلها أكثر سهولة.
علاوة على ذلك، أوصى فريق DeepSeek بإجراء اختبارات متعددة ومتوسطة النتائج كجزء من عملية القياس – وهو أمر أغفلته بسبب ضيق الوقت.
(8) دليل تفصيلي خطوة بخطوة
حتى هذه المرحلة، قمنا بتغطية المفاهيم الأساسية والاستنتاجات الرئيسية.
إذا كنت مستعدًا لتجربة عملية وتقنية، يقدم هذا القسم نظرة متعمقة على الآليات الداخلية والتنفيذ خطوة بخطوة. هذا الدليل التقني العملي سيوفر لك فهمًا شاملاً لكيفية عمل النظام.
للاطلاع على (أو استنساخ) مستودع GitHub المصاحب للمتابعة. يمكن العثور على متطلبات إعداد البيئة الافتراضية هنا.
(i) الإعداد الأولي – Ollama
نبدأ بتنزيل Ollama. تفضل بزيارة
صفحة تنزيل Ollama، واختر نظام التشغيل الخاص بك، واتبع تعليمات التثبيت المطابقة.
بمجرد اكتمال التثبيت، قم بتشغيل Ollama بالنقر المزدوج على تطبيق Ollama (لنظامي التشغيل Windows و macOS) أو تشغيل الأمر ollama serve في الوحدة الطرفية.
(ii) الإعداد الأولي – OpenAI simple-evals
إعداد simple-evals فريد نسبيًا.
في حين أن simple-evals يقدم نفسه كمكتبة، فإن غياب ملفات __init__.py في المستودع يعني أنه غير مهيكل كحزمة بايثون مناسبة، مما يؤدي إلى أخطاء الاستيراد بعد استنساخ المستودع محليًا. هذا يعني أنه ليس حزمة بايثون قياسية بالمعنى المتعارف عليه في هندسة البرمجيات.
نظرًا لأنه غير منشور أيضًا على PyPI ويفتقر إلى ملفات التعبئة القياسية مثل setup.py أو pyproject.toml، فلا يمكن تثبيته عبر pip. هذا يجعله تحديًا بعض الشيء للمطورين الجدد.
لحسن الحظ، يمكننا استخدام وحدات Git الفرعية كحل بديل ومباشر. هذه الوحدات تسمح بتضمين مستودع Git داخل مستودع آخر، مما يسهل إدارة التبعيات.
“`html
تسمح لنا وحدة Git الفرعية بتضمين محتويات مستودع Git آخر داخل مشروعنا. تسحب الملفات من مستودع خارجي (مثل simple-evals)، ولكنها تحتفظ بتاريخها منفصلاً.
يمكنك اختيار إحدى الطريقتين (أ أو ب) لسحب محتويات simple-evals:
(أ) إذا قمت باستنساخ مستودع مشروعي
يتضمن مستودع مشروعي بالفعل simple-evals كوحدة فرعية، لذا يمكنك فقط تشغيل:
git submodule update --init --recursive(ب) إذا كنت تضيفه إلى مشروع تم إنشاؤه حديثًا
لإضافة simple-evals يدويًا كوحدة فرعية، قم بتشغيل هذا:
git submodule add https://github.com/openai/simple-evals.git simple_evalsملاحظة: إن simple_evals في نهاية الأمر (مع شرطة سفلية) أمر بالغ الأهمية. فهو يحدد اسم المجلد، واستخدام واصلة بدلاً من ذلك (أي simple–evals) يمكن أن يؤدي إلى مشاكل في الاستيراد لاحقًا.
الخطوة الأخيرة (لكلا الطريقتين)
بعد سحب محتويات المستودع، يجب عليك إنشاء ملف __init__.py فارغ في مجلد simple_evals الذي تم إنشاؤه حديثًا حتى يمكن استيراده كوحدة. يمكنك إنشاؤه يدويًا، أو استخدام الأمر التالي:
touch simple_evals/__init__.py(iii) سحب نموذج DeepSeek-R1 عبر Ollama
الخطوة التالية هي تنزيل النموذج المقطر الذي تختاره محليًا (على سبيل المثال، 14B) باستخدام هذا الأمر:
يمكن العثور على قائمة بنماذج DeepSeek-R1 المتوفرة على Ollama هنا. للحصول على أفضل أداء، يوصى باستخدام أحدث إصدار من النموذج.
ollama pull deepseek-r1:14b(رابعًا) تحديد الإعدادات
نقوم بتحديد المعلمات في ملف YAML الخاص بالإعدادات، كما هو موضح أدناه:
# config/config.yaml MODEL_NAME: "deepseek-r1:14b" # Model name (match with Ollama model list) MODEL_TEMPERATURE: 0.6 # Set between 0.5 and 0.7 for DeepSeek-R1 EVAL_BENCHMARK: "gpqa" GPQA_VARIANT: "diamond" EVAL_N_EXAMPLES: 20
تم ضبط درجة حرارة النموذج على 0.6 (مقارنة بالقيمة الافتراضية النموذجية 0). يتبع هذا توصيات استخدام DeepSeek، التي تقترح نطاق درجة حرارة من 0.5 إلى 0.7 (يوصى بـ 0.6) لمنع التكرارات اللانهائية أو المخرجات غير المتماسكة. هذا الإعداد ضروري لتحسين جودة المخرجات وضمان اتساقها.
لا تفوت فرصة الاطلاع على توصيات استخدام DeepSeek-R1 الفريدة والمثيرة للاهتمام – خاصةً فيما يتعلق بالمعايير القياسية – لضمان الأداء الأمثل عند استخدام نماذج DeepSeek-R1.
EVAL_N_EXAMPLES هي المعلمة المستخدمة لتعيين عدد الأسئلة من المجموعة الكاملة المكونة من 198 سؤالًا والمستخدمة في التقييم. هذه المعلمة ضرورية لضبط عملية التقييم وفقًا للموارد المتاحة وأهداف الاختبار المحددة.
(v) إعداد كود Sampler (أداة أخذ العينات)
لدعم نماذج اللغة القائمة على Ollama ضمن إطار عمل simple-evals، نقوم بإنشاء فئة تغليف مخصصة باسم OllamaSampler وحفظها داخل utils/samplers/ollama_sampler.py. تعتبر أداة أخذ العينات (Sampler) مكونًا أساسيًا في اختبار وتقييم أداء نماذج اللغة.
# utils/samplers/ollama_sampler.py
import ollama
class OllamaSampler:
def __init__(self, model_name=None, temperature=0):
self.model_name = model_name
self.temperature = temperature
def __call__(self, prompt_messages):
prompt_text = prompt_messages[-1]["content"]
response = ollama.chat(
model=self.model_name,
messages=[{"role": "user", "content": prompt_text}],
options={"temperature": self.temperature}
)
response_content = response["message"]["content"]
return response_content
def _pack_message(self, content, role):
return {"role": role, "content": content}
في هذا السياق، يُقصد بـ sampler (أداة أخذ العينات) فئة Python تقوم بإنشاء مخرجات من نموذج لغة بناءً على مطالبة معينة. وتعتبر هذه الأداة حاسمة لضمان توليد استجابات متنوعة وممثلة من النموذج.
نظرًا لأن أدوات أخذ العينات الموجودة في simple-evals تغطي فقط موفري خدمات مثل OpenAI و Claude، فنحن بحاجة إلى فئة sampler توفر واجهة متوافقة مع Ollama. هذا يضمن التكامل السلس مع إطار التقييم.
تقوم OllamaSampler باستخراج مطالبة سؤال GPQA، وإرسالها إلى النموذج بدرجة حرارة محددة، وإرجاع استجابة نص عادي. وتعتبر درجة الحرارة (Temperature) معلمة هامة تتحكم في عشوائية المخرجات.
يتم تضمين طريقة _pack_message لضمان تطابق تنسيق الإخراج مع ما تتوقعه نصوص التقييم في simple-evals. هذا يضمن التوافق وسهولة التحليل.
6. إنشاء سكريبت تشغيل التقييم
يوضح الكود التالي كيفية إعداد تنفيذ التقييم في ملف main.py، بما في ذلك استخدام الفئة GPQAEval من مكتبة simple-evals لتشغيل اختبار GPQA المعياري.
الدالة run_eval() هي أداة تشغيل تقييم قابلة للتكوين تختبر نماذج اللغات الكبيرة (LLMs) من خلال Ollama على معايير مثل GPQA. هذه الدالة ضرورية لتقييم أداء النماذج بدقة.
# main.py
def run_eval():
start_time = time.time()
# Load configuration file
config = load_config("config/config.yaml")
# Initialize Ollama sampler (wrapper around Ollama chat)
ollama_sampler = OllamaSampler(model_name=config["MODEL_NAME"],
temperature=config["MODEL_TEMPERATURE"]
)
# Select evaluation class to use based on EVAL_BENCHMARK
eval_benchmark = config["EVAL_BENCHMARK"] # GPQA
print(f">>> Running {eval_benchmark} evaluation")
if eval_benchmark == "gpqa":
eval_class = GPQAEval
eval_kwargs = {
"n_repeats": config["EVAL_N_REPEATS"], # Default 1
"num_examples": config["EVAL_N_EXAMPLES"], # Set to 20
"variant": config["GPQA_VARIANT"], # GPQA-Diamond subset
}
else:
raise ValueError(
f"Unknown EVAL_BENCHMARK '{eval_benchmark}'."
)
# Instantiate and run the appropriate eval
evaluator = eval_class(**eval_kwargs)
results = evaluator(ollama_sampler) # Execute evaluation with sampler
end_time = time.time()
elapsed_seconds = end_time - start_time
minutes, seconds = divmod(elapsed_seconds, 60) # Compute total time taken
# Returned results is an EvalResult which includes list of SingleEvalResult and aggregated metrics
print(">>>> Overall Evaluation Metrics:", results.metrics)
print(">>>> Score:", results.score)
print(f">>>> Total Execution Time: {int(minutes)} min {seconds:.2f} sec")
if __name__ == "__main__":
# Run GPQA evaluation execution
run_eval()
تقوم الدالة بتحميل الإعدادات من ملف التهيئة، وإعداد فئة التقييم المناسبة من simple-evals، وتشغيل النموذج من خلال عملية تقييم موحدة. يتم حفظها في ملف main.py، والذي يمكن تنفيذه باستخدام الأمر python main.py. هذا يضمن عملية تقييم متسقة وقابلة للتكرار.
باتباع الخطوات المذكورة أعلاه، نكون قد نجحنا في إعداد وتنفيذ اختبار GPQA-Diamond المعياري على نموذج DeepSeek-R1 distilled. هذه العملية توفر رؤى قيمة حول قدرات النموذج.
خلاصة القول
في هذه المقالة، استعرضنا كيف يمكننا الجمع بين أدوات مثل Ollama و simple-evals من OpenAI لاستكشاف وتقييم النماذج المقطرة من DeepSeek-R1، مع التركيز على تقييم أداء نماذج اللغة الكبيرة.
قد لا تضاهي النماذج المقطرة النموذج الأصلي ذي الـ 671 مليار معلمة في معايير الاستدلال الصعبة مثل GPQA-Diamond حتى الآن. ومع ذلك، فإنها توضح كيف يمكن للتقطير توسيع الوصول إلى قدرات الاستدلال الخاصة بنماذج اللغة الكبيرة LLM. تحسين الوصول إلى نماذج اللغة الكبيرة هو هدف رئيسي في هذا المجال.
على الرغم من النتائج المتدنية في المهام المعقدة على مستوى الدكتوراه، قد تظل هذه المتغيرات الأصغر قابلة للتطبيق في سيناريوهات أقل تطلبًا، مما يمهد الطريق للنشر المحلي الفعال على نطاق أوسع من الأجهزة. هذا يساهم في نشر نماذج اللغة الكبيرة محليًا بكفاءة.
التعليقات مغلقة.