

كيف تضمن أنَّ حلول الذكاء الاصطناعي التي تعتمد عليها تعمل كما تتوقع؟
مقدمة موجزة لتقييمات الذكاء الاصطناعي (AI Evals)
يشهد الذكاء الاصطناعي التوليدي (Generative AI (GenAI)) تطورًا سريعًا، ولم يعد مجرد روبوتات دردشة ممتعة أو توليد صور مثير للإعجاب. عام 2025 هو العام الذي ينصب فيه التركيز على تحويل الضجة الإعلامية حول الذكاء الاصطناعي إلى قيمة حقيقية. تبحث الشركات في كل مكان عن طرق لدمج والاستفادة من GenAI في منتجاتها وعملياتها – لتقديم خدمة أفضل للمستخدمين، وتعزيز الكفاءة، والحفاظ على القدرة التنافسية، ودفع النمو. وبفضل واجهات برمجة التطبيقات (APIs) والنماذج المدربة مسبقًا من كبار المزودين، يبدو دمج GenAI أسهل من أي وقت مضى. ولكن إليك مربط الفرس: مجرد أن التكامل سهل، لا يعني أن حلول الذكاء الاصطناعي ستعمل على النحو المنشود بمجرد نشرها.

النماذج التنبؤية ليست جديدة حقًا: كبشر، كنا نتنبأ بالأشياء لسنوات، بدءًا رسميًا بالإحصاء. ومع ذلك، أحدث GenAI ثورة في مجال التنبؤ لأسباب عديدة:
- لا حاجة لتدريب النموذج الخاص بك أو أن تكون عالم بيانات لبناء حلول الذكاء الاصطناعي
- أصبح الذكاء الاصطناعي الآن سهل الاستخدام من خلال واجهات الدردشة وسهل الدمج من خلال واجهات برمجة التطبيقات (APIs)
- إطلاق العنان للعديد من الأشياء التي لم يكن من الممكن القيام بها أو كان من الصعب حقًا القيام بها من قبل
كل هذه الأشياء تجعل GenAI مثيرًا للغاية، ولكنه أيضًا محفوف بالمخاطر. على عكس البرامج التقليدية – أو حتى التعلم الآلي الكلاسيكي – يقدم GenAI مستوى جديدًا من عدم القدرة على التنبؤ. أنت لا تقوم بتنفيذ منطق حتمي، بل تستخدم نموذجًا مدربًا على كميات هائلة من البيانات، على أمل أن يستجيب حسب الحاجة. إذن كيف نعرف ما إذا كان نظام الذكاء الاصطناعي يفعل ما نعتزم القيام به؟ كيف نعرف ما إذا كان جاهزًا للتشغيل؟ الجواب هو التقييمات (Evaluations)، وهو المفهوم الذي سنستكشفه في هذا المنشور:
- لماذا لا يمكن اختبار أنظمة Genai بنفس طريقة البرامج التقليدية أو حتى التعلم الآلي الكلاسيكي (ML)
- لماذا تعتبر التقييمات أساسية لفهم جودة نظام الذكاء الاصطناعي الخاص بك وليست اختيارية (إلا إذا كنت تحب المفاجآت)
- أنواع مختلفة من التقييمات وتقنيات لتطبيقها في الممارسة العملية
سواء كنت مدير منتج أو مهندسًا أو أي شخص يعمل أو مهتمًا بالذكاء الاصطناعي، آمل أن يساعدك هذا المنشور في فهم كيفية التفكير النقدي في جودة أنظمة الذكاء الاصطناعي (ولماذا تعتبر التقييمات أساسية لتحقيق هذه الجودة!).
لا يمكن اختبار الذكاء الاصطناعي التوليدي كما هو الحال مع البرامج التقليدية – أو حتى التعلم الآلي الكلاسيكي
في تطوير البرمجيات التقليدية، تتبع الأنظمة منطقًا حتميًا: إذا حدث X، فسيحدث Y – دائمًا. إلا إذا حدث خطأ ما في نظامك الأساسي أو أدخلت خطأً في التعليمات البرمجية… وهو السبب في إضافة الاختبارات والمراقبة والتنبيهات. تُستخدم اختبارات الوحدة للتحقق من صحة كتل صغيرة من التعليمات البرمجية، واختبارات التكامل لضمان عمل المكونات معًا بشكل جيد، والمراقبة للكشف عما إذا كان هناك شيء معطل في الإنتاج. اختبار البرامج التقليدية يشبه التحقق من عمل الآلة الحاسبة. تقوم بإدخال 2 + 2، وتتوقع 4. واضح وحتمي، إما أن يكون صحيحًا أو خاطئًا.
ومع ذلك، فإن التعلم الآلي والذكاء الاصطناعي يدخلان عدم الحتمية والاحتمالات. بدلاً من تحديد السلوك بشكل صريح من خلال القواعد، نقوم بتدريب النماذج لتعلم الأنماط من البيانات. في الذكاء الاصطناعي، إذا حدث X، فإن الإخراج لم يعد Y مشفرًا بشكل ثابت، ولكنه تنبؤ بدرجة معينة من الاحتمالية، بناءً على ما تعلمه النموذج أثناء التدريب. يمكن أن يكون هذا قويًا جدًا، ولكنه يقدم أيضًا عدم اليقين: قد يكون للمدخلات المتطابقة مخرجات مختلفة بمرور الوقت، وقد تكون المخرجات المعقولة غير صحيحة بالفعل، وقد يظهر سلوك غير متوقع لسيناريوهات نادرة…
هذا يجعل أساليب الاختبار التقليدية غير كافية، بل وغير واردة في بعض الأحيان. يقترب مثال الآلة الحاسبة من محاولة تقييم أداء الطالب في امتحان مفتوح. لكل سؤال، والعديد من الطرق الممكنة للإجابة على السؤال، هل الإجابة المقدمة صحيحة؟ هل هي أعلى من مستوى المعرفة التي يجب أن يتمتع بها الطالب؟ هل اختلق الطالب كل شيء ولكنه يبدو مقنعًا للغاية؟ تمامًا مثل الإجابات في الامتحان، يمكن تقييم أنظمة الذكاء الاصطناعي، ولكنها تحتاج إلى طريقة أكثر عمومية ومرونة للتكيف مع المدخلات والسياقات وحالات الاستخدام المختلفة (أو أنواع الاختبارات).
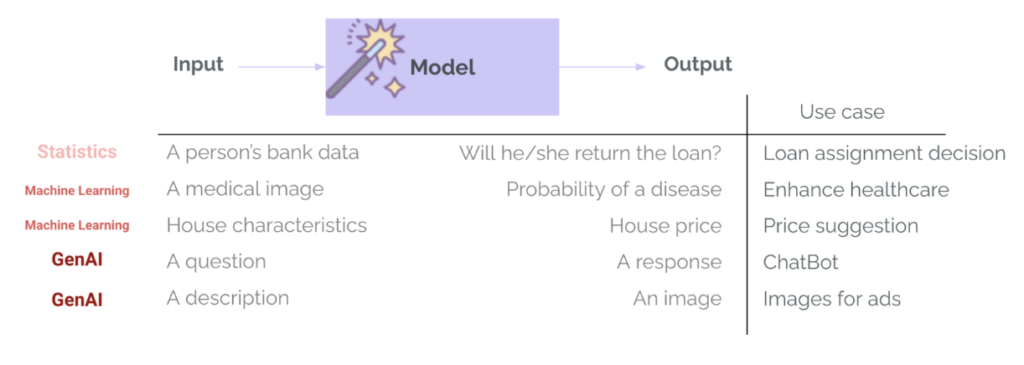
في التعلم الآلي التقليدي (ML)، تعد التقييمات بالفعل جزءًا راسخًا من دورة حياة المشروع. يتضمن تدريب نموذج على مهمة ضيقة مثل الموافقة على القروض أو الكشف عن الأمراض دائمًا خطوة تقييم – باستخدام مقاييس مثل الدقة، والاسترجاع، و RMSE، و MAE… يُستخدم هذا لقياس مدى جودة أداء النموذج، للمقارنة بين خيارات النماذج المختلفة، ولتحديد ما إذا كان النموذج جيدًا بما يكفي للانتقال إلى النشر. في GenAI، يتغير هذا عادةً: تستخدم الفرق نماذج تم تدريبها بالفعل واجتازت بالفعل تقييمات للأغراض العامة داخليًا من جانب مزود النموذج وعلى المعايير العامة. هذه النماذج جيدة جدًا في المهام العامة – مثل الإجابة على الأسئلة أو صياغة رسائل البريد الإلكتروني – وهناك خطر الإفراط في الوثوق بها لحالة الاستخدام المحددة الخاصة بنا. ومع ذلك، من المهم أن نسأل “هل هذا النموذج المذهل جيد بما يكفي لحالة الاستخدام الخاصة بي؟“. هذا هو المكان الذي يأتي فيه التقييم – لتقييم ما إذا كانت التنبؤات أو الأجيال جيدة لحالة الاستخدام والسياق والمدخلات والمستخدمين المحددين.

هناك اختلاف كبير آخر بين ML و GenAI: تنوع وتعقيد مخرجات النموذج. لم نعد نعيد الفئات والاحتمالات (مثل احتمال قيام العميل بإعادة القرض)، أو الأرقام (مثل سعر المنزل المتوقع بناءً على خصائصه). يمكن لأنظمة GenAI إرجاع أنواع عديدة من المخرجات، بأطوال ونغمات ومحتويات وتنسيقات مختلفة. وبالمثل، لم تعد هذه النماذج تتطلب مدخلات منظمة ومحددة للغاية، ولكنها عادةً ما تأخذ أي نوع من المدخلات تقريبًا – نصًا أو صورًا أو حتى صوتًا أو فيديو. لذلك يصبح التقييم أصعب بكثير.
لماذا تُعتبر عمليات التقييم ضرورية وليست اختيارية (إلا إذا كنت تفضل المفاجآت غير السارة)
تساعدك عمليات التقييم في قياس ما إذا كان نظام الذكاء الاصطناعي الخاص بك يعمل بالفعل بالطريقة التي تريدها، وما إذا كان النظام جاهزًا للتشغيل، وإذا كان الأمر كذلك، فهل يستمر في الأداء كما هو متوقع. فيما يلي تحليل لأسباب أهمية عمليات التقييم:
- تقييم الجودة: توفر عمليات التقييم طريقة منظمة لفهم جودة تنبؤات أو مخرجات الذكاء الاصطناعي الخاص بك وكيف ستندمج في النظام العام وحالة الاستخدام. هل الاستجابات دقيقة؟ مفيدة؟ متماسكة؟ ذات صلة؟
- تحديد كمية الأخطاء: تساعد التقييمات في تحديد كمية النسبة المئوية وأنواع وحجم الأخطاء. ما مدى تكرار حدوث الأخطاء؟ ما هي أنواع الأخطاء التي تحدث بشكل متكرر (مثل الإيجابيات الكاذبة، والهلوسة، وأخطاء التنسيق)؟
- تخفيف المخاطر: تساعدك على اكتشاف ومنع السلوك الضار أو المتحيز قبل أن يصل إلى المستخدمين – مما يحمي شركتك من المخاطر المتعلقة بالسمعة والمشكلات الأخلاقية والمشكلات التنظيمية المحتملة.
الذكاء الاصطناعي التوليدي، مع علاقات الإدخال والإخراج الحرة وتوليد النصوص الطويلة، يجعل التقييمات أكثر أهمية وتعقيدًا. عندما تسوء الأمور، يمكن أن تسوء للغاية. لقد رأينا جميعًا عناوين الأخبار حول روبوتات الدردشة التي تقدم نصائح خطيرة، ونماذج تولد محتوى متحيزًا، وأدوات الذكاء الاصطناعي التي تهلوس حقائق خاطئة.
“الذكاء الاصطناعي لن يكون مثاليًا أبدًا، ولكن باستخدام التقييمات (evals) يمكنك تقليل خطر الإحراج – الذي قد يكلفك المال أو المصداقية أو لحظة انتشار واسع على Twitter.“
كيف تحدد استراتيجية تقييم الذكاء الاصطناعي؟

إذًا، كيف نحدد تقييمات الذكاء الاصطناعي الخاصة بنا؟ لا توجد طريقة تقييم واحدة تناسب الجميع. تعتمد التقييمات على حالة الاستخدام المحددة ويجب أن تتماشى مع الأهداف المحددة لتطبيق الذكاء الاصطناعي الخاص بك. على سبيل المثال، إذا كنت تقوم ببناء محرك بحث، فقد تهتم بمدى ملاءمة النتائج. وإذا كان روبوت محادثة، فقد تهتم بمدى helpfulness والسلامة. وإذا كان مصنفًا، فمن المحتمل أن تهتم بالدقة وال precision. بالنسبة للأنظمة التي تتضمن خطوات متعددة (مثل نظام الذكاء الاصطناعي الذي يجري بحثًا، ويحدد أولويات النتائج ثم ينشئ إجابة)، غالبًا ما يكون من الضروري تقييم كل خطوة. الفكرة هنا هي قياس ما إذا كانت كل خطوة تساعد في تحقيق مقياس النجاح العام (ومن خلال هذا، فهم أين يتم تركيز التكرارات والتحسينات).
تشمل مجالات التقييم الشائعة ما يلي:
- الصحة والتحقق من الحقائق (Correctness & Hallucinations): هل المخرجات دقيقة من الناحية الواقعية؟ وهل يقوم النظام بتوليد معلومات غير صحيحة أو هلوسات؟
- الملاءمة (Relevance): هل المحتوى متوافق مع استعلام المستخدم أو السياق المقدم؟
- السلامة والتحيز والسمية (safety, bias, and toxicity)
- التنسيق (Format): هل المخرجات بالتنسيق المتوقع (مثل JSON، استدعاء دالة صالح)؟
- السلامة والتحيز والسمية (Safety, Bias & Toxicity): هل يقوم النظام بإنشاء محتوى ضار أو متحيز أو سام؟
مقاييس خاصة بالمهمة (Task-Specific Metrics). على سبيل المثال، في مهام التصنيف، يتم استخدام مقاييس مثل accuracy و precision، وفي مهام التلخيص ROUGE أو BLEU، وفي مهام إنشاء التعليمات البرمجية regex والتحقق من التنفيذ دون أخطاء.
كيف يتم حساب عمليات التقييم (Evals) فعليًا؟
بمجرد تحديد ما تريد قياسه، فإن الخطوة التالية هي تصميم حالات الاختبار الخاصة بك. ستكون هذه مجموعة من الأمثلة (كلما زاد عدد الأمثلة كان ذلك أفضل، ولكن مع تحقيق التوازن دائمًا بين القيمة والتكاليف) حيث لديك:
- مثال الإدخال: إدخال واقعي لنظامك بمجرد دخوله مرحلة الإنتاج.
- الناتج المتوقع (إن أمكن): الحقيقة الأساسية أو مثال للنتائج المرغوبة.
- طريقة التقييم: آلية تسجيل لتقييم النتيجة.
- النتيجة أو النجاح/الفشل: مقياس محسوب يقوم بتقييم حالة الاختبار الخاصة بك.
اعتمادًا على احتياجاتك ووقتك وميزانيتك، هناك العديد من التقنيات التي يمكنك استخدامها كطرق تقييم:
- أدوات التسجيل الإحصائية مثل BLEU و ROUGE و METEOR، أو قياس تشابه جيب التمام بين التضمينات – جيدة لمقارنة النص الذي تم إنشاؤه بالمخرجات المرجعية.
- مقاييس تعلم الآلة التقليدية مثل الدقة (Accuracy) والاسترجاع (Recall) والـ AUC – الأفضل للتصنيف مع البيانات المصنفة.
- نموذج لغوي كبير كلجنة تحكيم (LLM-as-a-Judge) استخدم نموذجًا لغويًا كبيرًا لتقييم المخرجات (على سبيل المثال، “هل هذه الإجابة صحيحة ومفيدة؟“). مفيد بشكل خاص عندما لا تتوفر بيانات مصنفة أو عند تقييم إنشاء مفتوح النهاية.
عمليات التقييم المستندة إلى التعليمات البرمجية استخدم التعابير النمطية أو قواعد المنطق أو تنفيذ حالة الاختبار للتحقق من صحة التنسيقات.
خلاصة القول
دعونا نجمع كل شيء معًا بمثال ملموس. تخيل أنك تقوم ببناء نظام لتحليل المشاعر لمساعدة فريق دعم العملاء لديك في تحديد أولويات رسائل البريد الإلكتروني الواردة.
الهدف هو التأكد من أن الرسائل الأكثر إلحاحًا أو سلبية تحصل على استجابات أسرع – مما يقلل من الإحباط ويحسن الرضا ويقلل من معدل فقدان العملاء. هذه حالة استخدام بسيطة نسبيًا، ولكن حتى في نظام مثل هذا، مع مخرجات محدودة، تهم الجودة: قد تؤدي التنبؤات السيئة إلى تحديد أولويات رسائل البريد الإلكتروني بشكل عشوائي، مما يعني أن فريقك يضيع الوقت مع نظام يكلف المال.
إذًا، كيف تعرف أن الحل الخاص بك يعمل بالجودة المطلوبة؟ أنت تقوم بالتقييم. فيما يلي بعض الأمثلة على الأشياء التي قد تكون ذات صلة لتقييمها في حالة الاستخدام المحددة هذه:
- التحقق من صحة التنسيق (Format Validation): هل يتم إرجاع مخرجات استدعاء نموذج اللغة الكبير (LLM) للتنبؤ بمشاعر البريد الإلكتروني بتنسيق JSON المتوقع؟ يمكن تقييم ذلك عبر فحوصات تعتمد على التعليمات البرمجية: regex، والتحقق من صحة المخطط، وما إلى ذلك.
- دقة تصنيف المشاعر (Sentiment Classification Accuracy): هل يصنف النظام المشاعر بشكل صحيح عبر مجموعة من النصوص – القصيرة والطويلة ومتعددة اللغات؟ يمكن تقييم ذلك باستخدام البيانات المصنفة باستخدام مقاييس التعلم الآلي التقليدية (ML metrics) – أو، إذا لم تكن التصنيفات متاحة، باستخدام نموذج اللغة الكبير (LLM) كحكم.
بمجرد أن يصبح الحل مباشرًا، سترغب أيضًا في تضمين المقاييس الأكثر ارتباطًا بالتأثير النهائي للحل الخاص بك:
- فعالية تحديد الأولويات (Prioritization Effectiveness): هل يتم توجيه وكلاء الدعم بالفعل نحو رسائل البريد الإلكتروني الأكثر أهمية؟ هل تتوافق تحديد الأولويات مع التأثير المطلوب على الأعمال؟
- التأثير النهائي على الأعمال (Final Business Impact): بمرور الوقت، هل يقلل هذا النظام من أوقات الاستجابة، ويقلل من معدل فقدان العملاء، ويحسن درجات الرضا؟
تعتبر التقييمات (Evals) أساسية لضمان بناء أنظمة الذكاء الاصطناعي (AI) المفيدة والآمنة والقيمة والجاهزة للمستخدمين في الإنتاج. لذلك، سواء كنت تعمل مع مصنف بسيط أو روبوت محادثة مفتوح النهاية، خذ الوقت الكافي لتحديد ما تعنيه عبارة “جيد بما فيه الكفاية” (الحد الأدنى من الجودة القابلة للتطبيق) – وقم ببناء التقييمات حوله لقياسه!
المراجع
[1] Your AI Product Needs Evals, Hamel Husain
[2] LLM Evaluation Metrics: The Ultimate LLM Evaluation Guide, Confident AI
[3] Evaluating AI Agents, deeplearning.ai + Arize
التعليقات مغلقة.