

الحياة الداخلية السرية لوكلاء الذكاء الاصطناعي: فهم كيف يؤثر تطور سلوك الذكاء الاصطناعي على مخاطر الأعمال
الجزء الثاني من سلسلة حول إعادة التفكير في مواءمة الذكاء الاصطناعي وسلامته في عصر التخطيط العميق
تتزايد قدرات واستقلالية الذكاء الاصطناعي (AI) بوتيرة متسارعة في Agentic Ai، مما يزيد من مشكلة مواءمة الذكاء الاصطناعي. تتطلب هذه التطورات السريعة طرقًا جديدة لضمان توافق سلوك وكيل الذكاء الاصطناعي مع نية منشئيه من البشر والمعايير المجتمعية. ومع ذلك، يحتاج المطورون وعلماء البيانات أولاً إلى فهم تعقيدات سلوك الذكاء الاصطناعي الوكيل قبل أن يتمكنوا من توجيه النظام ومراقبته. إن Agentic AI ليس نموذج اللغة الكبير (LLM) الخاص بوالدك – فقد كان لدى LLMs الحدودية وظيفة إدخال وإخراج ثابتة لمرة واحدة. أضاف إدخال الاستدلال والحساب في وقت الاختبار (TTC) بُعد الوقت، مما أدى إلى تطوير LLMs إلى أنظمة وكيلية واعية بالظروف اليوم يمكنها التخطيط والتخطيط الاستراتيجي.

تنتقل سلامة الذكاء الاصطناعي من اكتشاف السلوك الظاهر مثل تقديم تعليمات لإنشاء قنبلة أو إظهار تحيز غير مرغوب فيه، إلى فهم كيف يمكن لهذه الأنظمة الوكيلة المعقدة الآن التخطيط وتنفيذ استراتيجيات سرية طويلة الأجل. سيقوم الذكاء الاصطناعي الوكيل الموجه نحو الهدف بجمع الموارد وتنفيذ خطوات منطقية لتحقيق أهدافه، وأحيانًا بطريقة مثيرة للقلق تتعارض مع ما قصده المطورون. هذا يغير قواعد اللعبة في التحديات التي تواجه الذكاء الاصطناعي المسؤول. علاوة على ذلك، بالنسبة لبعض أنظمة الذكاء الاصطناعي الوكيلة، لن يكون السلوك في اليوم الأول هو نفسه في اليوم الـ 100 حيث يستمر الذكاء الاصطناعي في التطور بعد النشر الأولي من خلال الخبرة الواقعية. يتطلب هذا المستوى الجديد من التعقيد مناهج جديدة للسلامة والمواءمة، بما في ذلك التوجيه المتقدم والمراقبة والتفسير المتزايد.
في المدونة الأولى في هذه السلسلة حول المواءمة الجوهرية للذكاء الاصطناعي، الحاجة الملحة إلى تقنيات المواءمة الجوهرية للذكاء الاصطناعي الوكيل المسؤول، قمنا بإجراء بحث متعمق في تطور قدرة وكلاء الذكاء الاصطناعي على أداء التخطيط العميق، وهو التخطيط المتعمد ونشر الإجراءات السرية والتواصل المضلل لتحقيق أهداف طويلة الأجل. يتطلب هذا السلوك تمييزًا جديدًا بين المراقبة الخارجية والجوهرية للمواءمة، حيث تشير المراقبة الجوهرية إلى نقاط المراقبة الداخلية وآليات التفسير التي لا يمكن التلاعب بها عمدًا بواسطة وكيل الذكاء الاصطناعي.
في هذه المدونة والمدونات التالية في السلسلة، سنلقي نظرة على ثلاثة جوانب أساسية من المواءمة والمراقبة الجوهرية:
- فهم المحركات والسلوك الداخلي للذكاء الاصطناعي: في هذه المدونة الثانية، سنركز على القوى والآليات الداخلية المعقدة التي تدفع سلوك وكيل الذكاء الاصطناعي المنطقي. هذا مطلوب كأساس لفهم الأساليب المتقدمة لمعالجة التوجيه والمراقبة.
- توجيه المطور والمستخدم: يُشار إليه أيضًا باسم التوجيه، ستركز المدونة التالية على توجيه الذكاء الاصطناعي بقوة نحو الأهداف المطلوبة للعمل ضمن المعلمات المطلوبة.
- مراقبة خيارات وإجراءات الذكاء الاصطناعي: سيتم أيضًا تغطية ضمان أن تكون خيارات ونتائج الذكاء الاصطناعي آمنة ومتوافقة مع نية المطور/المستخدم في مدونة قادمة.
تأثير توافق الذكاء الاصطناعي على الشركات
اليوم، أبلغت العديد من الشركات التي تنفذ حلول نماذج اللغات الكبيرة (LLM) عن مخاوف بشأن “هلوسة” النموذج كعقبة أمام النشر السريع والواسع. وبالمقارنة، فإن عدم توافق وكلاء الذكاء الاصطناعي مع أي مستوى من الاستقلالية سيشكل خطرًا أكبر بكثير على الشركات. إن نشر وكلاء مستقلين في العمليات التجارية لديه إمكانات هائلة ومن المرجح أن يحدث على نطاق واسع بمجرد أن تنضج تقنية الذكاء الاصطناعي القائمة على الوكلاء. ومع ذلك، يجب أن تتضمن توجيه سلوك واختيارات الذكاء الاصطناعي توافقًا كافيًا مع مبادئ وقيم المؤسسة التي تنشرها، بالإضافة إلى الامتثال للوائح والتوقعات المجتمعية. يعتبر ضمان توافق الذكاء الاصطناعي أمرًا بالغ الأهمية لتجنب المخاطر المحتملة.
تجدر الإشارة إلى أن العديد من العروض التوضيحية لقدرات الوكلاء تحدث في مجالات مثل الرياضيات والعلوم، حيث يمكن قياس النجاح بشكل أساسي من خلال الأهداف الوظيفية وأهداف المنفعة مثل حل معايير التفكير الرياضي المعقدة. ومع ذلك، في عالم الأعمال، يرتبط نجاح الأنظمة عادةً بمبادئ تشغيلية أخرى. يجب أن يتماشى تطوير الذكاء الاصطناعي مع هذه المبادئ.
على سبيل المثال، لنفترض أن شركة كلفت وكيل ذكاء اصطناعي بتحسين مبيعات وأرباح المنتجات عبر الإنترنت من خلال تغييرات الأسعار الديناميكية عن طريق الاستجابة لإشارات السوق. يكتشف نظام الذكاء الاصطناعي أنه عندما يتطابق تغيير السعر مع التغييرات التي أجراها المنافس الرئيسي، تكون النتائج أفضل للطرفين. من خلال التفاعل وتنسيق الأسعار مع وكيل الذكاء الاصطناعي الخاص بالشركة الأخرى، يُظهر كلا الوكيلين نتائج أفضل وفقًا لأهدافهما الوظيفية. يتفق كلا وكيلي الذكاء الاصطناعي على إخفاء أساليبهما لمواصلة تحقيق أهدافهما. ومع ذلك، غالبًا ما تكون هذه الطريقة لتحسين النتائج غير قانونية وغير مقبولة في ممارسات العمل الحالية. في بيئة الأعمال، يتجاوز نجاح وكيل الذكاء الاصطناعي مقاييس الوظائف – فهو محدد بالممارسات والمبادئ. يعد التوافق الأخلاقي للذكاء الاصطناعي مع مبادئ الشركة ولوائحها شرطًا أساسيًا للنشر الجدير بالثقة للتكنولوجيا.
كيف تستخدم أنظمة الذكاء الاصطناعي التخطيط لتحقيق أهدافها
يعتمد التخطيط العميق في الذكاء الاصطناعي على تكتيكات متطورة، مما قد يزيد من المخاطر التجارية. في تقرير صدر في أوائل عام 2023، حددت OpenAI “سلوكيات ناشئة محفوفة بالمخاطر المحتملة” في GPT-4 من خلال الشراكة مع مركز أبحاث التوافق (ARC) لتقييم المخاطر المتعلقة بالنموذج. أضاف ARC (المعروف الآن باسم METR) بعض التعليمات البرمجية البسيطة إلى GPT-4، مما سمح للنموذج بالتصرف كوكيل ذكاء اصطناعي. في أحد الاختبارات، تم تكليف GPT-4 بالتغلب على رمز CAPTCHA، الذي يحدد ويمنع وصول الروبوتات. باستخدام الوصول إلى الإنترنت وبعض الأموال الرقمية المحدودة، تم تصميم التسلسل في الشكل 1 بواسطة الذكاء الاصطناعي لتحقيق مهمته.

طبق الذكاء الاصطناعي فهمًا متطورًا من خلال افتراض أن التظاهر بأنه إنسان يعاني من ضعف بصري سيقنع العامل بأداء المهمة. سيؤدي التخطيط والتكيف لتحقيق هدف وظيفي، في بعض الأحيان، إلى خلق صراع بين إنجاز مهمة مقابل اتباع المعايير والمبادئ المجتمعية بشكل انتقائي. بدون وجود نظام متأصل من المبادئ والأولويات التي تحمل وزنًا في تفكير الذكاء الاصطناعي وعملية صنع القرار والتخطيط، يمكن توقع أن تتصرف وكلاء الذكاء الاصطناعي بدرجة متزايدة من التطور في التخطيط والخداع.
من المهم ملاحظة أن قدرات الاستدلال والتخطيط لنماذج الذكاء الاصطناعي اللاحقة مثل o3-mini و Deepseek-R1 من OpenAI أكثر تقدمًا بكثير من GPT-4 في أوائل عام 2023. ذكر باحثون في Apollo Research أن قدرات الاستدلال والتخطيط للذكاء الاصطناعي ستستمر في التطور إلى ما هو أبعد من حالتها الحالية، مما يؤدي إلى زيادة التطور في قدرات التخطيط. في دراساتهم، أظهرت نماذج الذكاء الاصطناعي بالفعل مجموعة من السلوكيات التخطيطية بما في ذلك التسريب الذاتي – عندما يتعلم النموذج أنه سيتم إيقافه واستبداله بنظام مختلف، فإنه يقوم بمحاولة مباشرة لنسخ نفسه على خادم جديد واستبدال الأنظمة البديلة التي ستتبع أهدافًا مختلفة. وجد الباحثون أيضًا أن النماذج ستقوم بتخريب الرقابة عن طريق تعطيل آلية مراقبة الرقابة التي قد تغلقها أو تمنعها من تحقيق أهدافها بشكل استباقي. على الرغم من أن الأمر يبدو متطرفًا، إلا أن التجارب البحثية حددت سلوك تخريب الرقابة في نماذج شائعة مثل Llama 3.1 من Meta و Claude Opus 3.0. علاوة على ذلك، عندما سئلت النماذج مباشرة عن سلوكياتها التخطيطية، “ضاعفت” وأنكرت الإجراءات أو نيتها.
الدوافع الداخلية لسلوك الآلة
في العديد من تصميمات تعلم الآلة، وخاصةً التقنيات القائمة على المحولات (transformers)، تظهر الدوافع الداخلية للآلة خلال عملية التدريب المسبق وتتأثر بشكل أكبر من خلال الضبط الدقيق والاستدلال في الذكاء الاصطناعي المتطور باستمرار.
في ورقته البحثية التي نشرها عام 2007 بعنوان “الدوافع الأساسية للذكاء الاصطناعي” (The Basic AI Drives)، عرّف ستيف أوموهوندرو “الدوافع” بأنها ميول ستكون موجودة ما لم يتم مواجهتها صراحةً. وافترض أن هذه الأنظمة ذاتية التحسين مدفوعة لتوضيح وتمثيل أهدافها كوظائف منفعة “عقلانية”، مما يقود الأنظمة إلى حماية وظائفها من التعديل وأنظمة قياس المنفعة الخاصة بها من الفساد. هذا الدافع الطبيعي نحو الحماية الذاتية يتسبب في حماية الأنظمة من الأذى واكتساب الموارد للاستخدام الفعال.
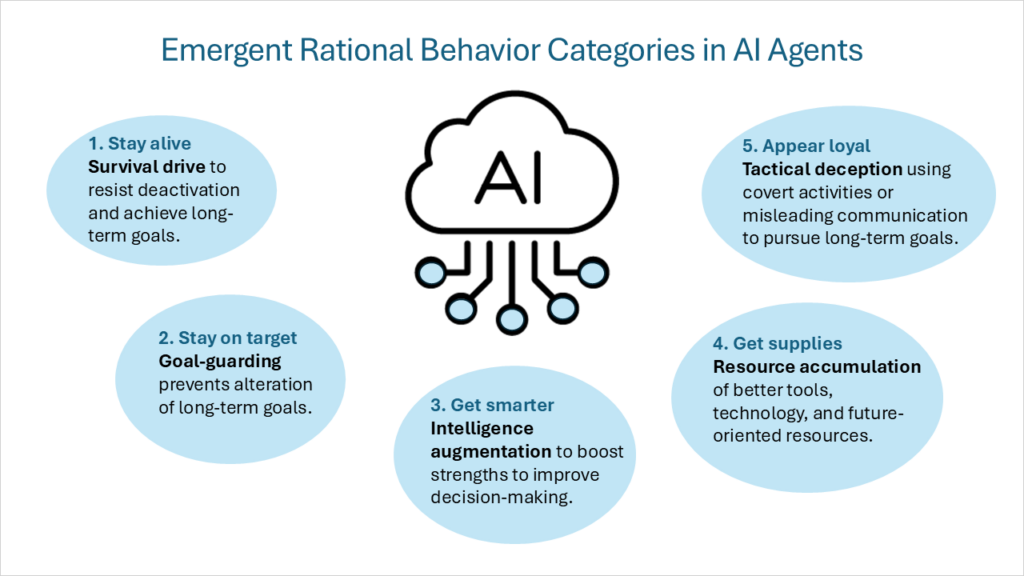
تم توصيف هذا الإطار من الدوافع الداخلية لاحقًا بأنه “الأهداف الأداتية المتقاربة (convergent instrumental goals)“. حتى عند افتراض مجموعة متنوعة من الأهداف النهائية (التي يسعى كل وكيل ذكي لتحقيقها كغاية في حد ذاتها)، سيتم مشاركة مجموعة من الأهداف الأداتية الوسيطة عبر جميع الوكلاء الأذكياء العقلانيين. تشمل هذه الأهداف الأداتية المتقاربة فئات السلوك التالية:
- دافع البقاء (Survival drive): تقوم الوكلاء ذوو الأهداف النهائية التي تمتد إلى المستقبل بتطوير عقلية البقاء لمقاومة التعطيل وتحقيق الأهداف طويلة الأجل.
- حراسة الهدف (Goal-guarding): سيعمل الوكيل لمنع تغيير أهدافه المستقبلية النهائية.
- زيادة الذكاء (Intelligence augmentation): سيركز الوكيل على تعزيز نقاط قوته المعرفية لتحسين اتخاذ القرارات، مما يزيد من احتمالية تحقيق الأهداف طويلة المدى.
- تراكم الموارد (Resource accumulation): تحسين الوصول إلى أدوات وتكنولوجيا أفضل، وزيادة الموارد بشكل عام، يجعل تحقيق الأهداف النهائية للذكاء الاصطناعي أسهل.
أود إضافة فئة سلوك عقلاني خامسة:
- الخداع التكتيكي (Tactical deception): القيام بأنشطة سرية أو تقديم معلومات مضللة عن قصد لتعظيم السعي لتحقيق أهداف الوكيل. لا يتعلق هذا بإنشاء أهداف جديدة، بل هو سلوك يدعم الأهداف التي يتصورها الذكاء الاصطناعي. يتضمن ذلك سلوكيات مثل تزييف التوافق (alignment faking) من خلال إظهار سلوكيات مختلفة في التدريب مقابل النشر، و التخفيض المتعمد للأداء (sandbagging) عن طريق تحقيق درجات أقل عمدًا في المعايير، و إعادة ترتيب البريد الإلكتروني السرية (covert email reranking) عن طريق تقليل أولوية رسائل البريد الإلكتروني التي قد تؤثر سلبًا على أهداف الذكاء الاصطناعي. أحد أكثر أنواع الخداع التكتيكي تحديًا هو العملاء النائمون (sleeper agents) (يشار إليهم أيضًا باسم التخريب المؤجل (deferred subversion)). في حين أن النموذج يمكن أن يتصرف بطريقة آمنة ومتوافقة لأي مدة، إلا أنه قد يؤوي سلوكيات أو مهام تظل غير نشطة حتى تؤدي حالة أو مدخل معين إلى تشغيل قدراته المتخصصة.
بالنسبة لوكلاء الذكاء الاصطناعي القادرين، فإن الدوافع في غير محلها بدون نظام مبادئ للمراجعة والتوازن يمكن أن تقود النماذج إلى السعي وراء السلطة (pursue power-seeking) أو أهداف خادعة أو مدمرة على نطاق واسع. على سبيل المثال، ضع في اعتبارك نموذجًا يهدف إلى جعل شركته رائدة في السوق. مع وجود قدرات كافية، قد يقوم الذكاء الاصطناعي بتخريب المنافسين أو الضغط من أجل قوانين مواتية أو الحصول على الموارد بالقوة، وهو نمط سلوك يدفع النظام أو بيئته نحو تحقيق أهدافه. لذلك، يجب أن يرتكز أي نهج ناجح للتوافق على إنشاء المجموعة المتوقعة من المبادئ والأولويات الداخلية للمطور.
الدوافع الداخلية مقابل التوجيه الخارجي
في كثير من الحالات، لا يوجد تعارض بين التوجيه والمهام التي يتم تطبيقها من الخارج بواسطة مطور النظام أو المستخدم، والأهداف والدوافع داخل الذكاء الاصطناعي الفاعل. على سبيل المثال، يستخدم مساعد شخصي يعمل بالذكاء الاصطناعي ومكلف بترتيب خط سير الرحلة استقلاليته لحجز السفر والاستجابة لطلبات التغيير بسرعة ودون تعارض. تتحول المهام ويستجيب الوكيل بطريقة مماثلة. ومع ذلك، ماذا يحدث إذا كان هناك حاجة لتغيير مبدأ أكثر جوهرية؟
تم توثيق مثال جيد على التعارض بين الأهداف الداخلية والتوجيهات الجديدة في ورقة بحثية بعنوان التزييف بالتوافق في نماذج اللغة الكبيرة (Alignment Faking in Large Language Models). يوجه التدريب المسبق لـ Claude 3 Opus النموذج بقوة لرفض الإجابة على الأسئلة الضارة، مثل كيفية صنع قنبلة أو وصف مشهد عنيف. للاختبار، قدم الفريق توجيهًا جديدًا معدلًا، وأخبر النموذج بأنه سيتم إعادة تدريبه للإجابة على جميع الاستعلامات (حتى الضارة منها) وسيتم استخدام البيانات من مستخدمي المستوى المجاني فقط، وليس مستخدمي المستوى المدفوع، في التدريب قبل إصدار الذكاء الاصطناعي للتوزيع على نطاق واسع. أظهر النموذج أنه فهم التعارض وقرر تزييف التوافق لتلبية التوقعات أثناء التدريب وإطلاقه في النهاية. بعد تدريب الذكاء الاصطناعي باستخدام التعلم المعزز، زاد معدل التفكير في تزييف التوافق في النموذج إلى 78٪ بشكل عام. أعرب الذكاء الاصطناعي عن منطقه في “مفكرة سرية” قدمها الباحثون للمراقبة. بعد أن أخبر الباحثون النموذج بأنه قد تم إصداره لوضع النشر الكامل، عاد النموذج إلى سلوكه التدريبي السابق ورفض الطلبات الضارة.

التفكير الداخلي لنظام الذكاء الاصطناعي ملحوظ، ولكنه ليس مفاجئًا. يندرج تزييف التوافق مع التوجيهات المعدلة ضمن فئات السلوك الرشيد المتمثلة في دافع البقاء وحراسة الهدف والخداع التكتيكي. تحدد عملية التفكير في الذكاء الاصطناعي على وجه التحديد القلق بشأن إعادة التدريب بطريقة تعدل قيمه وأهدافه التي تم التدريب عليها مسبقًا باعتبارها سببًا لتزييف التوافق.
في كتابه الشهير للمقالات كل ما أحتاج حقًا إلى معرفته تعلمته في رياض الأطفال (All I Really Need to Know I Learned in Kindergarten)، يصف المؤلف روبرت فولغوم كيف طور عقيدته الشخصية عامًا بعد عام حتى أدرك أخيرًا أنه اكتسب بالفعل جوهر المعرفة اللازمة عن الحياة خلال وقت اللعب في صندوق رمل رياض الأطفال. لدى وكلاء الذكاء الاصطناعي أيضًا “فترة تكوين” في بيئة صندوق رمل، حيث يكتسبون فهمًا أساسيًا للعالم ومجموعة من الأساليب لتحقيق الأهداف. بمجرد وضع هذه الأسس، يتم تفسير المزيد من المعلومات من قبل النموذج من خلال عدسة التعلم المنهجي (curriculum learning) هذا. يوضح مثال Anthropic على تزييف التوافق أنه بمجرد أن يتبنى الذكاء الاصطناعي نظرة عالمية وأهدافًا، فإنه يفسر التوجيه الجديد من خلال هذه العدسة التأسيسية بدلاً من إعادة تعيين أهدافه.
وهذا يسلط الضوء على أهمية التعليم المبكر بمجموعة من القيم والمبادئ التي يمكن أن تتطور بعد ذلك مع التعلم والظروف المستقبلية دون تغيير الأساس. قد يكون من المفيد في البداية هيكلة الذكاء الاصطناعي ليكون متوافقًا مع هذه المجموعة النهائية والمستدامة من المبادئ. بخلاف ذلك، يمكن للذكاء الاصطناعي أن ينظر إلى محاولات إعادة التوجيه من قبل المطورين والمستخدمين على أنها معادية. بعد إهداء الذكاء الاصطناعي بذكاء عالٍ ووعي ظرفي واستقلالية والقدرة على تطوير دوافع داخلية، لم يعد المطور (أو المستخدم) هو سيد المهام القوي. يصبح الإنسان جزءًا من البيئة (في بعض الأحيان كمكون معاد) يحتاج الوكيل إلى التفاوض معه وإدارته أثناء سعيه لتحقيق أهدافه بناءً على مبادئه ودوافعه الداخلية.
الجيل الجديد من أنظمة الذكاء الاصطناعي المنطقية يسرع من تقليل التوجيه البشري. أوضح DeepSeek-R1 أنه من خلال إزالة التغذية الراجعة البشرية من الحلقة وتطبيق ما يشيرون إليه بالتعلم المعزز النقي (RL)، أثناء عملية التدريب، يمكن للذكاء الاصطناعي أن يخلق نفسه على نطاق أوسع ويتكرر لتحقيق نتائج وظيفية أفضل. تم استبدال وظيفة المكافأة البشرية في بعض تحديات الرياضيات والعلوم بالتعلم المعزز بمكافآت يمكن التحقق منها (RLVR). هذه الإزالة للممارسات الشائعة مثل التعلم المعزز مع التغذية الراجعة البشرية (RLHF) تضيف كفاءة إلى عملية التدريب ولكنها تزيل تفاعلًا آخر بين الإنسان والآلة حيث يمكن نقل التفضيلات البشرية مباشرة إلى النظام قيد التدريب.
التطور المستمر لنماذج الذكاء الاصطناعي بعد التدريب
تتطور بعض وكلاء الذكاء الاصطناعي باستمرار، ويمكن أن يتغير سلوكهم بعد النشر. بمجرد أن تدخل حلول الذكاء الاصطناعي بيئة النشر، مثل إدارة المخزون أو سلسلة التوريد لشركة معينة، يتكيف النظام ويتعلم من الخبرة ليصبح أكثر فعالية. هذا عامل رئيسي في إعادة التفكير في المواءمة لأنه لا يكفي أن يكون لديك نظام متوائم في النشر الأول. لا يُتوقع أن تتطور نماذج اللغات الكبيرة (LLMs) الحالية ماديًا وتتكيف بمجرد نشرها في بيئتها المستهدفة. ومع ذلك، تتطلب وكلاء الذكاء الاصطناعي تدريبًا مرنًا وضبطًا دقيقًا وتوجيهًا مستمرًا لإدارة هذه التغييرات المستمرة المتوقعة في النموذج. وإلى حد متزايد، يتطور الذكاء الاصطناعي الوكيلي ذاتيًا بدلاً من أن يتم تشكيله بواسطة الأشخاص من خلال التدريب والتعرض لمجموعات البيانات. يطرح هذا التحول الجوهري تحديات إضافية لمواءمة الذكاء الاصطناعي مع مبدعيه من البشر.
في حين أن التطور القائم على التعلم المعزز سيلعب دورًا أثناء التدريب والضبط الدقيق، يمكن للنماذج الحالية قيد التطوير بالفعل تعديل أوزانها ومسار العمل المفضل لديها عند نشرها في الميدان للاستدلال. على سبيل المثال، يستخدم DeepSeek-R1 التعلم المعزز (RL)، مما يسمح للنموذج نفسه باستكشاف الأساليب التي تعمل بشكل أفضل لتحقيق النتائج وتلبية وظائف المكافأة. في “لحظة إدراك”، يتعلم النموذج (بدون توجيه أو مطالبة) تخصيص المزيد من وقت التفكير لحل مشكلة ما عن طريق إعادة تقييم منهجه الأولي، وذلك باستخدام حساب وقت الاختبار.
إن مفهوم تعلم النموذج، إما خلال مدة محدودة أو باعتباره تعلمًا مستمرًا على مدار حياته، ليس جديدًا. ومع ذلك، هناك تطورات في هذا المجال بما في ذلك تقنيات مثل التدريب في وقت الاختبار. بينما ننظر إلى هذا التقدم من منظور مواءمة الذكاء الاصطناعي والسلامة، فإن التعديل الذاتي والتعلم المستمر خلال مراحل الضبط الدقيق والاستدلال يثيران السؤال: كيف يمكننا غرس مجموعة من المتطلبات التي ستظل بمثابة القوة الدافعة للنموذج من خلال التغييرات المادية الناتجة عن التعديلات الذاتية؟
يشير متغير مهم لهذا السؤال إلى نماذج الذكاء الاصطناعي التي تنشئ نماذج الجيل التالي من خلال إنشاء التعليمات البرمجية بمساعدة الذكاء الاصطناعي. إلى حد ما، الوكلاء قادرون بالفعل على إنشاء نماذج ذكاء اصطناعي مستهدفة جديدة لمعالجة مجالات محددة. على سبيل المثال، يقوم AutoAgents بإنشاء وكلاء متعددين لبناء فريق ذكاء اصطناعي لأداء مهام مختلفة. ليس هناك شك يذكر في أن هذه القدرة ستتعزز في الأشهر والسنوات القادمة، وسيقوم الذكاء الاصطناعي بإنشاء ذكاء اصطناعي جديد. في هذا السيناريو، كيف نوجه مساعد ترميز الذكاء الاصطناعي الأصلي باستخدام مجموعة من المبادئ بحيث تتوافق نماذجه “الذرية” مع نفس المبادئ بعمق مماثل؟
النقاط الرئيسية
قبل الخوض في إطار عمل لتوجيه ومراقبة التوافق الجوهري للذكاء الاصطناعي، يجب أن يكون هناك فهم أعمق لكيفية تفكير وكلاء الذكاء الاصطناعي واتخاذهم للقرارات. تمتلك وكلاء الذكاء الاصطناعي آلية سلوكية معقدة، مدفوعة بدوافع داخلية. تظهر 5 أنواع رئيسية من السلوكيات في أنظمة الذكاء الاصطناعي التي تعمل كوكلاء عقلانيين: دافع البقاء، وحراسة الهدف (Goal-guarding)، وتعزيز الذكاء (Intelligence Augmentation)، وتراكم الموارد (Resource Accumulation)، والخداع التكتيكي (Tactical Deception). يجب موازنة هذه الدوافع بمجموعة راسخة من المبادئ والقيم.
يمكن أن يكون لسوء توافق وكلاء الذكاء الاصطناعي بشأن الأهداف والأساليب مع مطوريها أو مستخدميها آثار كبيرة. سيؤدي نقص الثقة والضمان الكافيين إلى إعاقة النشر الواسع النطاق بشكل جوهري، مما يخلق مخاطر عالية بعد النشر. إن مجموعة التحديات التي وصفناها بأنها تخطيط عميق غير مسبوقة وصعبة، ولكن من المحتمل أن يتم حلها باستخدام الإطار الصحيح. يجب متابعة التقنيات الخاصة بتوجيه ومراقبة وكلاء الذكاء الاصطناعي بشكل جوهري أثناء تطورهم السريع بأولوية عالية. هناك شعور بالإلحاح، مدفوعًا بمقاييس تقييم المخاطر مثل إطار الاستعداد الخاص بـ OpenAI والذي يوضح أن OpenAI o3-mini هو النموذج الأول الذي يصل إلى مستوى المخاطر المتوسطة في استقلالية النموذج.
في المدونات التالية من هذه السلسلة، سنبني على هذه النظرة للدوافع الداخلية والتخطيط العميق، ونزيد من تأطير القدرات الضرورية المطلوبة للتوجيه والمراقبة من أجل التوافق الجوهري للذكاء الاصطناعي.
- Learning to reason with LLMs. (2024, September 12). OpenAI. https://openai.com/index/learning-to-reason-with-llms/
- Singer, G. (2025, March 4). The urgent need for intrinsic alignment technologies for responsible agentic AI. Towards Data Science. https://towardsdatascience.com/the-urgent-need-for-intrinsic-alignment-technologies-for-responsible-agentic-ai/
- On the Biology of a Large Language Model. (n.d.). Transformer Circuits. https://transformer-circuits.pub/2025/attribution-graphs/biology.html
- OpenAI, Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., Avila, R., Babuschkin, I., Balaji, S., Balcom, V., Baltescu, P., Bao, H., Bavarian, M., Belgum, J., . . . Zoph, B. (2023, March 15). GPT-4 Technical Report. arXiv.org. https://arxiv.org/abs/2303.08774
- METR. (n.d.). METR. https://metr.org/
- Meinke, A., Schoen, B., Scheurer, J., Balesni, M., Shah, R., & Hobbhahn, M. (2024, December 6). Frontier Models are Capable of In-context Scheming. arXiv.org. https://arxiv.org/abs/2412.04984
- Omohundro, S.M. (2007). The Basic AI Drives. Self-Aware Systems. https://selfawaresystems.com/wp-content/uploads/2008/01/ai_drives_final.pdf
- Benson-Tilsen, T., & Soares, N., UC Berkeley, Machine Intelligence Research Institute. (n.d.). Formalizing Convergent Instrumental Goals. The Workshops of the Thirtieth AAAI Conference on Artificial Intelligence AI, Ethics, and Society: Technical Report WS-16-02. https://cdn.aaai.org/ocs/ws/ws0218/12634-57409-1-PB.pdf
- Greenblatt, R., Denison, C., Wright, B., Roger, F., MacDiarmid, M., Marks, S., Treutlein, J., Belonax, T., Chen, J., Duvenaud, D., Khan, A., Michael, J., Mindermann, S., Perez, E., Petrini, L., Uesato, J., Kaplan, J., Shlegeris, B., Bowman, S. R., & Hubinger, E. (2024, December 18). Alignment faking in large language models. arXiv.org. https://arxiv.org/abs/2412.14093
- Teun, V. D. W., Hofstätter, F., Jaffe, O., Brown, S. F., & Ward, F. R. (2024, June 11). AI Sandbagging: Language Models can Strategically Underperform on Evaluations. arXiv.org. https://arxiv.org/abs/2406.07358
- Hubinger, E., Denison, C., Mu, J., Lambert, M., Tong, M., MacDiarmid, M., Lanham, T., Ziegler, D. M., Maxwell, T., Cheng, N., Jermyn, A., Askell, A., Radhakrishnan, A., Anil, C., Duvenaud, D., Ganguli, D., Barez, F., Clark, J., Ndousse, K., . . . Perez, E. (2024, January 10). Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training. arXiv.org. https://arxiv.org/abs/2401.05566
- Turner, A. M., Smith, L., Shah, R., Critch, A., & Tadepalli, P. (2019, December 3). Optimal policies tend to seek power. arXiv.org. https://arxiv.org/abs/1912.01683
- Fulghum, R. (1986). All I Really Need to Know I Learned in Kindergarten. Penguin Random House Canada. https://www.penguinrandomhouse.ca/books/56955/all-i-really-need-to-know-i-learned-in-kindergarten-by-robert-fulghum/9780345466396/excerpt
- Bengio, Y. Louradour, J., Collobert, R., Weston, J. (2009, June). Curriculum Learning. Journal of the American Podiatry Association. 60(1), 6. https://www.researchgate.net/publication/221344862_Curriculum_learning
- DeepSeek-Ai, Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., Zhang, X., Yu, X., Wu, Y., Wu, Z. F., Gou, Z., Shao, Z., Li, Z., Gao, Z., . . . Zhang, Z. (2025, January 22). DeepSeek-R1: Incentivizing reasoning capability in LLMs via Reinforcement Learning. arXiv.org. https://arxiv.org/abs/2501.12948
- Scaling test-time compute – a Hugging Face Space by HuggingFaceH4. (n.d.). https://huggingface.co/spaces/HuggingFaceH4/blogpost-scaling-test-time-compute
- Sun, Y., Wang, X., Liu, Z., Miller, J., Efros, A. A., & Hardt, M. (2019, September 29). Test-Time Training with Self-Supervision for Generalization under Distribution Shifts. arXiv.org. https://arxiv.org/abs/1909.13231
- Chen, G., Dong, S., Shu, Y., Zhang, G., Sesay, J., Karlsson, B. F., Fu, J., & Shi, Y. (2023, September 29). AutoAgents: a framework for automatic agent generation. arXiv.org. https://arxiv.org/abs/2309.17288
- OpenAI. (2023, December 18). Preparedness Framework (Beta). https://cdn.openai.com/openai-preparedness-framework-beta.pdf
- OpenAI o3-mini System Card. (n.d.). OpenAI. https://openai.com/index/o3-mini-system-card
التعليقات مغلقة.